Визуализация в Superset
Теория: Drilldown и интерактивные фильтры
Сегодня поговорим о фильтрах в Apache Superset. Это важная тема, потому что фильтры помогают нам и нашим пользователям работать с данными более эффективно. К этому моменту мы уже умеем создавать подключения к базам, датасеты, графики и дашборды.
В Superset есть три основных типа фильтров:
- Фильтры на графиках (для исходных данных)
- Интерактивные фильтры на дашбордах (для пользователей)
- Drilldown (фильтры с детализацией)
Зачем нам нужны фильтры? Вот основные случаи:
- Когда нужно проанализировать только часть данных (например, продажи за определенный период)
- Для очистки данных (убрать некорректные значения)
- При высокой агрегации, когда надо отбросить ненужные данные
Давайте на практике разберем каждый тип фильтров.
Фильтры на графиках
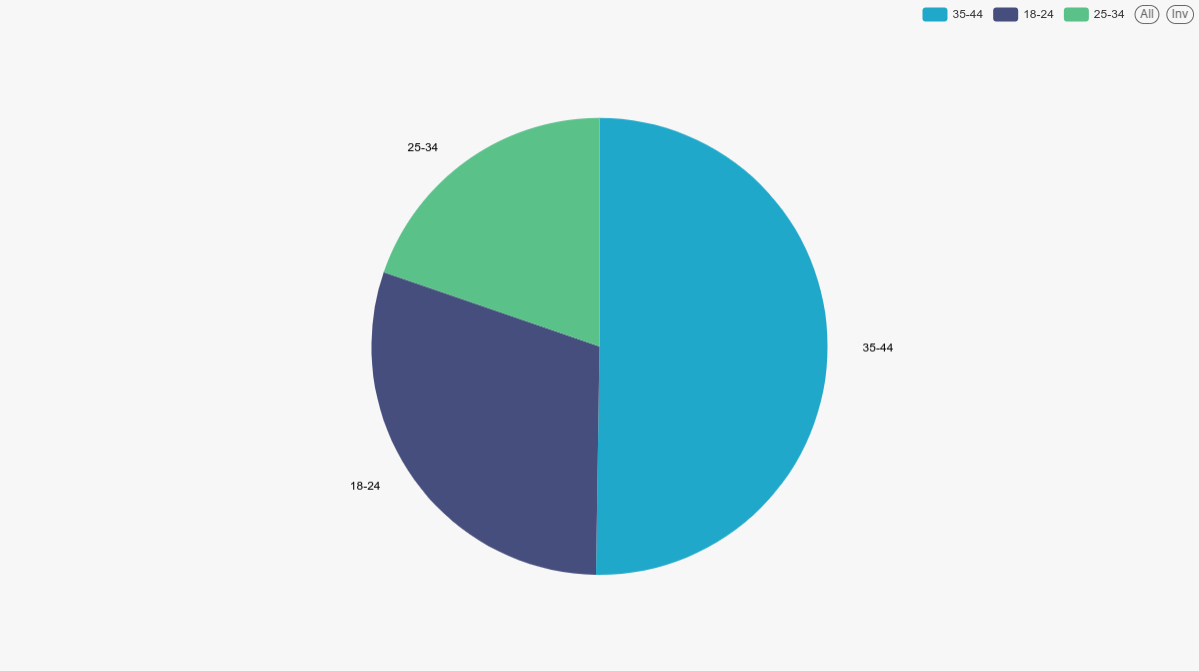
Вернемся к нашей круговой диаграмме. В качестве dimension у нас была возрастная группа, а в метрике – сумма продаж.
Теперь добавим фильтр по возрасту. Например категории до "35-44" включительно:
Интерактивные фильтры на дашборде
Это фильтры, которыми пользуются конечные пользователи. Давайте добавим такой фильтр:
- Открываем дашборд
- Нажимаем на иконку воронки
- Выбираем "Add or Edit Filters"
- Настраиваем новый фильтр.Выберем числовой и укажем колонку total_revenue и выберем к каким графикам применять
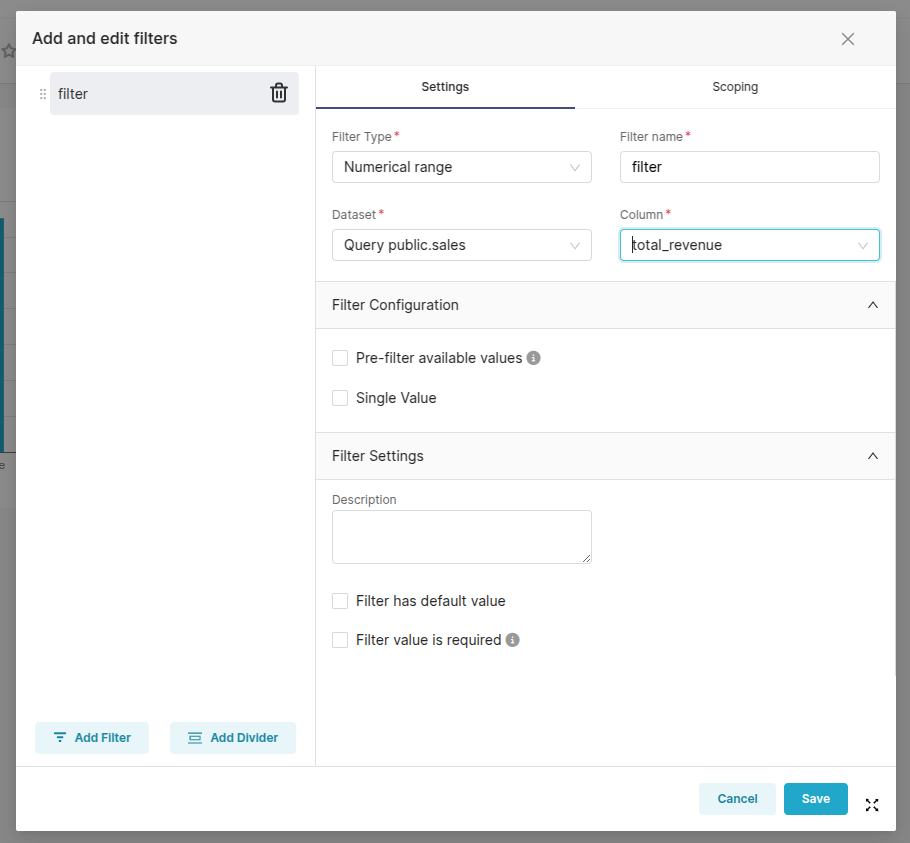
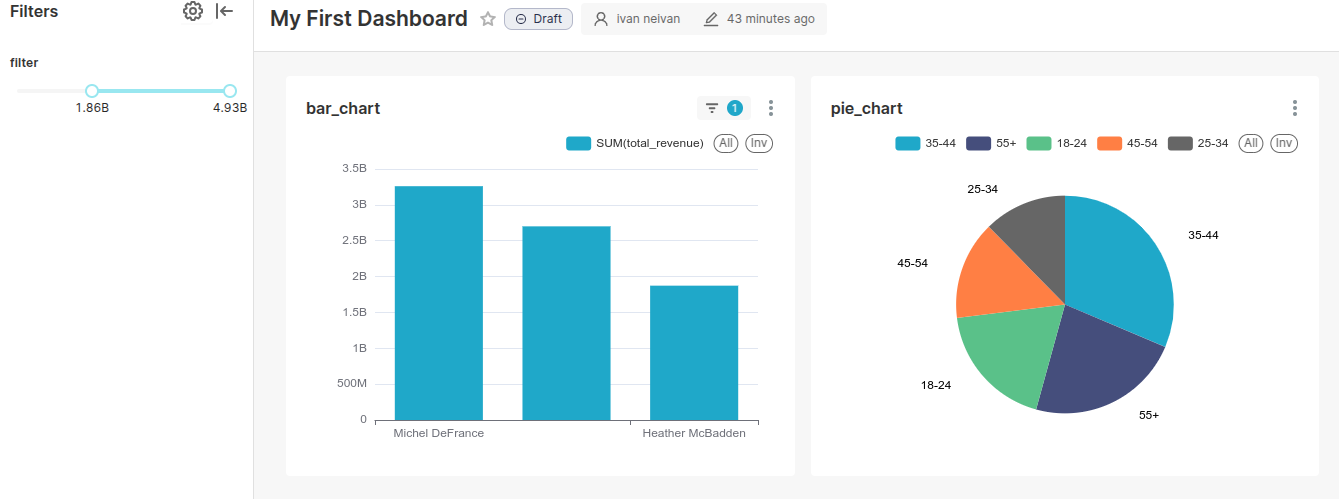
Помимо всего, можно задать значение по умолчанию, добавить описание и настроить сортировку.
Drilldown фильтры
Это продвинутый способ фильтрации с детализацией. Например, если у нас есть круговая диаграмма с продажами по категориям, мы можем сделать drilldown по типу клиента.
Выводы
Сегодня мы разобрались с фильтрами в Apache Superset. Они помогают нам и пользователям работать с данными более эффективно. Для графиков лучше использовать постоянные фильтры, если данные всегда нужны в определенном разрезе. Интерактивные фильтры удобны, когда пользователям нужно самим исследовать данные. Drilldown особенно полезен для детального анализа конкретных показателей.
Фильтры делают наши дашборды более гибкими и полезными. Пользователи могут сами исследовать данные, не обращаясь каждый раз к аналитикам за новыми разрезами информации.

