Аналитика на SQL
Теория: Сортировка результатов
Сортировка данных — это важный инструмент для анализа данных. Она позволяет указывать, в каком порядке нужно выводить результаты запроса. Таким образом мы можем с легкостью найти наибольшие или наименьшие значения в столбце — продукт с самой высокой ценой или магазин с наибольшим количеством продаж. Так мы выделяем наиболее значимые данные и сосредотачиваемся на их анализе.
В этом уроке мы обсудим, как сортировать данные с помощью оператора ORDER BY.
Базовый синтаксис
Синтаксис сортировки данных в SQL с использованием оператора ORDER BY выглядит так:
Рассмотрим его подробнее:
<названия_колонок>— список столбцов, которые мы хотим выбрать<таблица>— название таблицы, из которой мы выбираем данные<название_колонки1>, <название_колонки2>, ...— столбцы, по которым мы хотим отсортировать данные[ASC|DESC]— необязательная опция, которая указывает направление сортировки
Обсудим последнюю опцию. С ее помощью мы задаем направление сортировки, используя ключевые слова:
ASC— сортировка по возрастанию (от меньшего к большему, от более ранних дат к более поздним)DESC— сортировка в обратную сторону, то есть по убыванию
Когда мы используем оператор ORDER BY без указания направления сортировки, по умолчанию используется ASC.
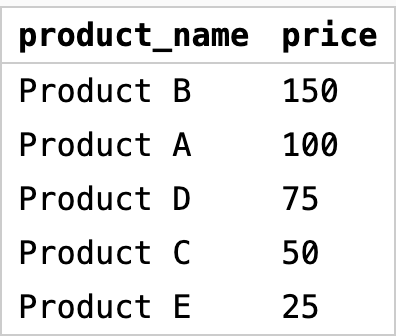
Возьмем нашу базу продаж и отсортируем список продуктов по убыванию цены:
В этом примере мы выбираем столбцы product_name и price из таблицы products, а затем сортируем результаты по столбцу price в порядке убывания. Таким образом, мы получим список продуктов от дорогих к дешевым:
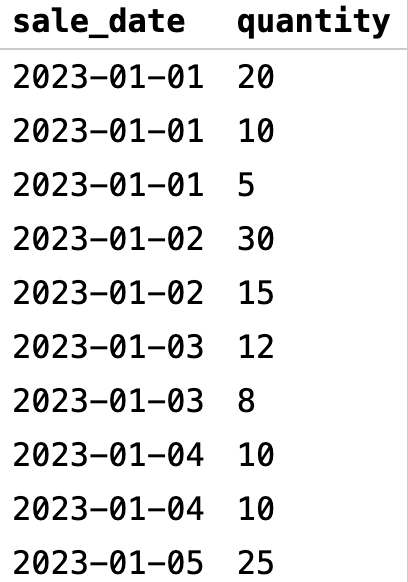
Также мы можем сортировать данные по нескольким столбцам. Например, отсортируем таблицу продаж по дате и количеству продаж:
В этом примере мы выбираем столбцы sale_date и quantity из таблицы sales. Затем мы сортируем результаты сначала по столбцу sale_date в порядке возрастания, а затем — по столбцу quantity в порядке убывания. В итоге получаем список продаж, отсортированных сначала по дате, а затем — по количеству продаж:
Мы можем указывать не только имена столбцов в операторе ORDER BY, но еще и использовать порядок сортировки столбцов. Это делается с помощью выражения ORDER BY 1, 2, ..., n, где числа соответствуют позиции столбцов в выборке.
Это удобно, когда мы работаем с большими наборами данных и хотим отсортировать результаты по нескольким столбцам. Здесь можно не прописывать имена столбцов, а просто можно перечислить их позиции. Так удобнее и читать запрос, и писать его.
Возьмем для примера следующий запрос:
В ответ на него мы получим такой результат:
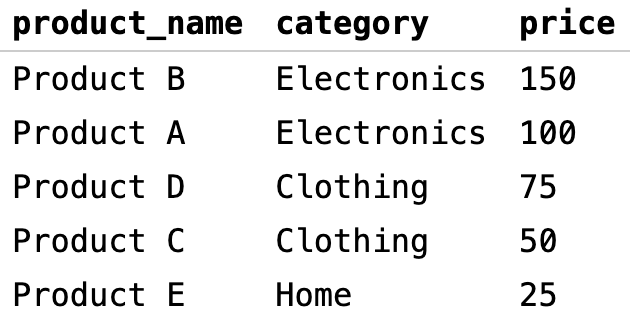
Здесь мы указываем позиции двух столбцов:
3для сортировки по столбцуprice2для сортировки по столбцуcategory
Такой подход позволяет нам сократить код и сделать его более лаконичным.
Обработка нулевых значений
При работе с оператором ORDER BY нужно не забывать про NULL-значения — с ними есть несколько тонкостей.
В языке SQL нет единого стандарта как сортировать данные с NULL, и каждый провайдер, авторы базы данных, решает сам. Поэтому положение NULL-значений может отличаться в разных БД. Например, в MySQL NULL будут впереди при сортировке по возрастанию, тогда как в PostreSQL в самом конце.
Потому, если ваши данные содержат NULL, то важно явно указывать, где должны располагаться значения NULL в результирующем наборе данных. Для этого можно пользоваться двумя расширениями:
NULLS LAST— оно указывает, что значенияNULLдолжны быть в конце результата. Обычно его используют при сортировке по возрастаниюNULLS FIRST— оно указывает, что значенияNULLдолжны быть в начале результата. Его используют в сортировке по убыванию
Оба расширения помогают убрать значения NULL, чтобы они не влияли на порядок вывода ненулевых значений.
Предположим, у нас есть таблица customers с информацией о клиентах. В ней есть столбцы customer_id, customer_name и age. Создадим новую таблицу с NULL-значениями в столбце age:
Выведем данные с помощью такого запроса:
Новая таблица будет выглядеть так:

Теперь попробуем убрать нулевые значения в начало или конец списка.
Отсортируем по возрастанию с расширением NULLS LAST:
Результат будет следующим:

Как видим, значения NULL отображаются в конце результата после всех ненулевых значений.
Похожим образом работает сортировка по убыванию с расширением NULLS FIRST:
Получаем:

Здесь значения NULL отображаются в начале результата перед всеми ненулевыми значениями.
Как видите, расширения NULLS LAST и NULLS FIRST позволяют контролировать положение значений NULL и адаптировать результаты запроса так, чтобы нам было удобно работать с результатами.
Сортировка с агрегацией
Кроме того, сортировку данных можно сочетать с агрегатными функциями — COUNT, SUM и AVG. Таким образом, можно найти самые частые или самые редкие повторяющиеся значения в столбце. Например, можно найти самый популярный продукт или клиента с наибольшим количеством заказов.
Например, отсортируем продукты по количеству продаж:
Получаем таблицу:
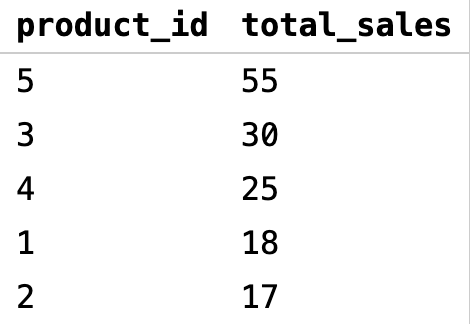
Разберемся, что происходит в этом коде:
SELECT product_id, SUM(quantity) AS total_sales— выбираем столбецproduct_id, вычисляем сумму продаж для каждого уникальногоproduct_idи задаем псевдонимtotal_salesдля результирующего столбца с суммой продажFROM sales— указываем, что данные берутся из таблицыsalesGROUP BY product_id— группируем данные по уникальным значениям столбцаproduct_id. Это означает, что в результате мы увидимproduct_id— отдельную строку для каждого уникального значенияORDER BY total_sales DESC— сортируем результаты по столбцуtotal_salesв порядке убывания от большего к меньшему
Если коротко, этот код возвращает результаты запроса, в которых продукты отображаются в порядке убывания общей суммы продаж. Продукт с наибольшей суммой продаж будет первым в результате, а продукт с наименьшей суммой — в самом конце.
Сортировка с оператором LIMIT
Кроме того, мы можем отсортировать данные одновременно с ограничением размера выборки. В этом помогает оператор LIMIT. Это полезно, когда мы хотим вывести несколько значений из начала или конца результирующего набора.
Для примера выберем из нашей базы пять продуктов с самой высокой ценой:
Здесь мы сортируем данные по столбцу price в обратном порядке (DESC). Затем мы используем оператор LIMIT и ограничиваем выборку пятью первыми результатами:
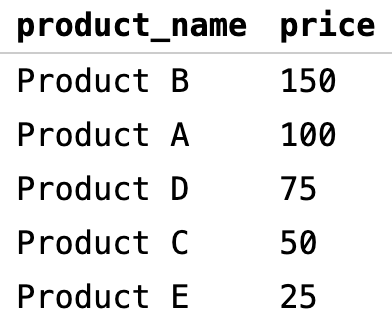
Это очень удобно при работе с большими объемами данных — можно вывести не все соответствующие результаты, а только значимые для анализа.
Выводы
В этом уроке мы изучили сортировку данных. Она помогает структурировать информацию, выделять значимые значения, определять тенденции и принимать обоснованные решения на основе анализа данных. Подведем краткие итоги этого урока:
- Данные сортируются с помощью оператора
ORDER BY, который позволяет управлять порядком вывода результатов запроса - Синтаксис оператора
ORDER BYвключает список столбцов, по которым мы хотим отсортировать данные - По умолчанию сортировка происходит по возрастанию (
ASC), но можно и указать сортировку по убыванию (DESC) - Можно сортировать данные по нескольким столбцам, указывая их имена или позиции в выборке
- Расширения
NULLS LASTиNULLS FIRSTпомогают указать положение значенийNULLв результирующем наборе - С помощью
LIMITможно выводить не все результаты сортировки, а ограниченное их количество — например, первые пять значений

