Python: Pandas
Теория: Визуализация данных
При анализе информации и данных часто нужно строить графики, диаграммы и гистограммы. Визуализация помогает оценивать масштабы значений, сравнивать показатели, понимать тренды и многое другое.
В библиотеке Pandas есть встроенный функционал для большинства типов графиков. Эти методы построены на базе библиотеки Matplotlib — одного из популярных среди аналитиков решений для визуализации на Python. В этом уроке мы познакомимся с часто используемыми в анализе данных инструментами визуализации библиотеки Pandas и научимся применять их на практике.
Работать будем на датасете кликов с сайтов четырех магазинов одной сети:
В данных есть ошибки: пропущенные, отрицательные и сильно завышенные значения кликов.
Влияние ошибок в данных на результаты анализа
Чтобы построить линейный график, используем метод plot():
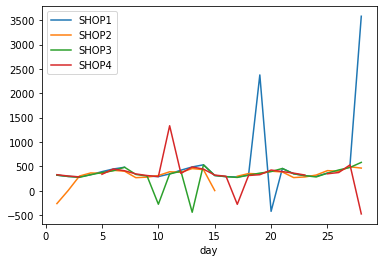
На графике видны разрывы, завышенные и отрицательные значения — это говорит о наличии ошибок.
Важно отметить техническую деталь при отрисовке графиков. Если использовать Jupyter Notebook, то для вывода графика достаточно выполнить код выше. Если писать код в виде обычного Python скрипта и выполнять его в терминале, то код необходимо дополнить методом отрисовки plt.show() из библиотеки matplotlib следующим образом:
Далее по тексту будем придерживаться способа для Jupyter Notebook.
Чтобы построить график конкретного магазина, необходимо указать его метку в качестве индекса и применить тот же метод plot():
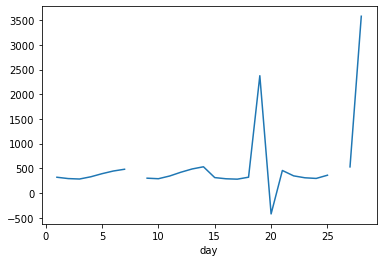
Разрывы стали еще более наглядными. Есть пропуски для данного магазина.
Начнем подготовку данных. Заполним пропуски средним значением для кликов по всем магазинам:
Избавимся от отрицательных и слишком больших значений следующим методом. Найдем среднее и стандартное отклонение от него. Порядка 70% всех значений будет укладываться в интервал, указанный ниже:
Зададим маску, с помощью верхней границы данного интервала и значения в десять кликов в качестве минимального ограничения:
Применим данную маску для фильтрации:
Посмотрим, как изменился график кликов первого магазина:
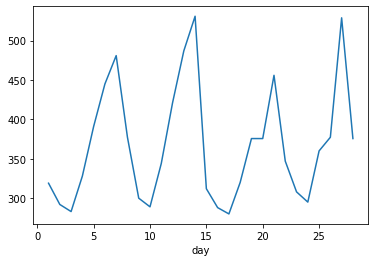
Временная шкала не поменялась, при этом визуально график сильно разнится с предыдущим. На таком графике уже прослеживаются особенности и закономерности в изменении значений со временем.
Также посмотрим на всю сеть:
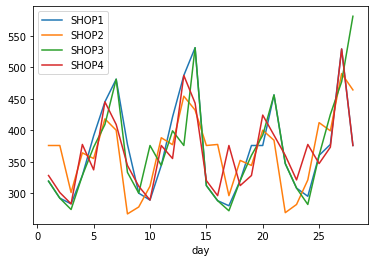
Эти графики показывают, как наличие ошибок в данных влияет на качество их анализа. После обработки на всех магазинах стала прослеживаться сезонность — волны кликов по выходным дням.
Кроме визуального анализа и построения гипотез о закономерностях в данных используют продвинутые алгоритмы машинного обучения. Указанным алгоритмам непросто выучить закономерности в данных при наличии в них ошибок. Аналитику необходимо перед анализом всегда готовить данные.
Сравнительный анализ показателей
Типы графиков могут быть разными. Задается тип с использованием параметра kind. На примере ниже показаны столбчатые диаграммы для первых семь дней. С их помощью можно производить анализ динамики изменений кликов по всей сети или же сравнивать значения в разрезе дней:
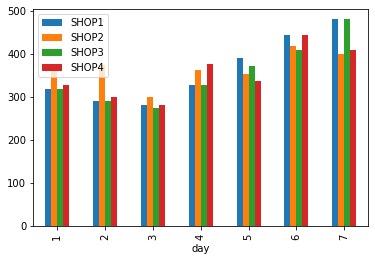
По данной столбчатой диаграмме можно сказать, что кликов на сайте магазина SHOP2 в начале недели было больше, чем во всех остальных по сети — первые три столбца слева. Также возрастает тренд в кликах ближе к выходным дням — размер столбцов увеличивается слева направо.
Статистический анализ
Анализировать статистические показатели можно с помощью визуализации плотности распределения кликов. Чтобы получить ее, нужно построить гистограмму, которая также задается через параметр kind:

Для первого магазина количество кликов смещено к значениям 300-350.
Для второго магазина наиболее типичным являются случаи кликов в интервале 350-400 в день:

Интегральные показатели
Чтобы сравнить интегральные показатели, можно использовать горизонтальные столбчатые диаграммы. В примере ниже задействован параметр fontsize, который отвечает за размер шрифта:

Одним из часто встречаемых в презентациях типов диаграмм является представление интегральных данных в виде пирога — круговые диаграммы:

Обе из диаграмм выше показывают, что в целом показатели кликов по магазинам практически совпадают.
Поиск зависимостей в данных
Чтобы найти зависимости в данных, используются различные подходы. Одним из них — корреляционный анализ. Чтобы найти в данных линейные закономерности, используют корреляцию Пирсона. При этом такой характер зависимости величин можно увидеть и на точечном графике.
Параметр scatter позволяет построить точки с координатами (x, y). В качестве значений координат возьмем подневные значения двух магазинов:
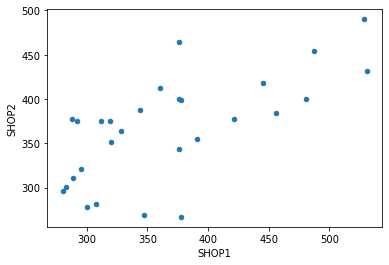
На примере выше показано, как расположились точки для 1 и 2 магазина. При этом зависимость здесь не усматривается. Но если посмотреть на пару 1 и 3 магазина, то ситуация меняется:
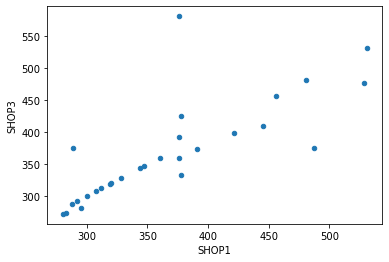
Несмотря на отклонения, точки расположились вдоль прямой — прослеживается линейная зависимость.
Выводы
В этом уроке мы рассмотрели различные типы графиков, которые доступны в Pandas для визуализации данных. С их помощью на практических примерах были продемонстрированы:
- Эффекты ошибок данных на результаты анализа
- Способы интегральной оценки показателей
- Подходы к визуализации зависимостей в данных
Визуализация данных упрощает:
- Поиск выбросов и пропущенных значений
- Анализ статистических и интегральных характеристик
- Формулирование гипотез о закономерностях
Для аналитика визуализация является необходимым инструментом. Выполнение указанных выше операций может быть невозможным при работе с большими объемами данных.

