Terraform: Основы
Теория: Практика Terraform
Terraform позволяет хранить описание облачной инфраструктуры в виде кода. Мы можем получить готовую к работе инфраструктуру со всеми зависимостями, выполнив всего одну команду — terraform apply.
В этом уроке мы попрактикуемся с Terraform и попробуем с его помощью развернуть с нуля готовую к работе инфраструктуру: создадим базу и сервер, свяжем их друг с другом, поставим на сервер приложение и подключим его к базе.
Подключение Terraform к облаку
Для начала организуем в проекте доступ к нашему облаку. Создадим папку с проектом и добавим в него файл .gitignore, в котором исключим рабочие файлы Terraform и секреты:
secret.*
.terraform
*.backup
Добавим файл providers.tf, в котором опишем нужный нам провайдер и его параметры подключения:
Объявим используемые там переменные в variables.tf.
Рекомендуем настроить консольную утилиту для облака. В этом случае через нее можно получить токен и сразу сконвертировать его в нужную нам переменную:
Команда выполнит запрос к облаку, извлечет из ответа строку с токеном и сохранит ее в файл secret.auto.tfvars.
Можно получить токен и другим способом. Главное сохранить его в секретный *.auto.tfvars.
Допишем к токену значения переменных yc_cloud_id и yc_folder_id — это id облака и каталога, в которых будем работать.
Теперь перейдем к описанию ресурсов. Поскольку в примере мы используем облако Yandex, нам нужно будет развернуть базовую сетевую инфраструктуру, в которой будут размещаться виртуальные машины и кластеры баз данных.
Сетевая связность
Для нашей инфраструктуры будет достаточно одной виртуальной сети yandex_vpc_network и подсети yandex_vpc_subnet:
Мы описали сетевые ресурсы и дали им одинаковые имена. Поскольку это разные ресурсы, конфликтов из-за одинакового имени не будет, а в интерфейсе облака мы явно увидим, что управляется Terraform.
Такая сетевая архитектура является спецификой облака Yandex. В нее можно не углубляться, главное для понимания:
- Подсеть предоставляет диапазон IP-адресов, которые мы можем использовать для наших серверов и баз данных
- Сеть включает в себя подсети, ресурсы в которых могут общаться друг с другом
Разместим в этой сетевой инфраструктуре облачную базу данных.
Кластер БД
Опишем ресурс облачного кластера БД PostgreSQL. Добавим в него пользователя и создадим базу:
В ресурсах пользователя и базы данных сразу пропишем зависимость от кластера.
Для создания пользователя и самой базы мы будем использовать sensitive-переменные db_user, db_password и db_name. Их необходимо объявить, а затем добавить значения в наш secret.auto.tfvars:
db_name = "hexlet"
db_user = "me"
db_password = "bvcdV6sdBS7AXZs"
Теперь опишем сервер и настроим так, чтобы при развертывании инфраструктуры на нем запускалось приложение. Приложение будет подключаться к кластеру БД.
Сервер и приложение
Запустим на сервере приложение wiki.js, которое можно развернуть с помощью Docker. Это избавит нас от установки дополнительных пакетов на сервер. Единственное, что нам потребуется для запуска — наличие на сервере Docker.
Облако предоставляет готовый образ на базе Ubuntu с предустановленным Docker.
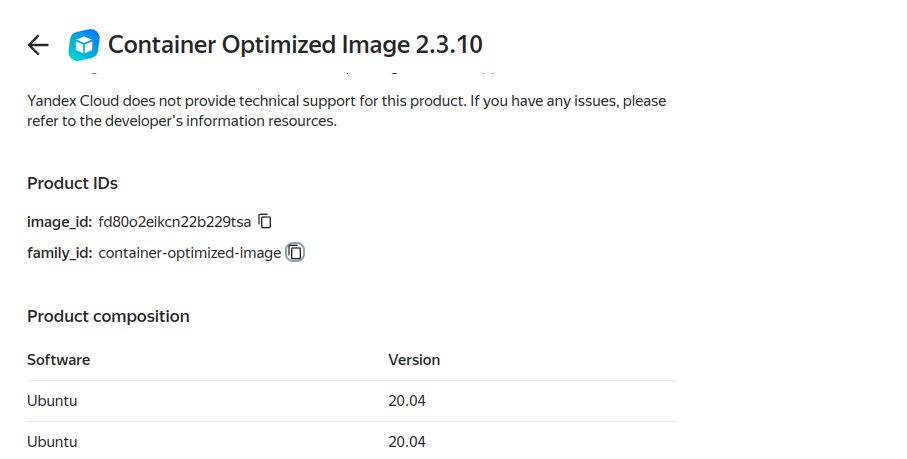
Мы можем скопировать id этого образа или использовать data source, чтобы получить актуальный образ по family ID: container-optimized-image.
Опишем сервер с помощью ресурса yandex_compute_instance:
Мы задаем для сервера:
- Выделенные ресурсы
- Образ виртуальной машины
- Подсеть, в которую он будет помещен
- Метаданные для инициации
Также для сетевого интерфейса машины задаем nat = true, чтобы машине был выдан внешний IP-адрес.
Не хватает описания запуска приложения и передачи ему параметров базы данных. Сделаем это с помощью Terraform provisioner. Провижнеры позволяют выполнять различные операции в процессе развертывания инфраструктуры — создавать файлы, выполнять скрипты локально или на новых созданных машинах.
Мы будем использовать провижнер remote-exec. Он подключается к серверу с помощью параметров, описанных в блоке connection. Там он выполняет операции, описанные в блоке inline.
И connection, и provisioner нужно добавить внутрь ресурса yandex_compute_instance. Допишем их ниже блока metadata:
В connection мы настроили подключение по ssh под пользователем ubuntu. Для этого использовали наш локальный приватный ключ. Провижнер будет подключаться по адресу self.network_interface[0].nat_ip_address — в это поле после создания сервера сохранится внешний IP-адрес сервера. Когда провижнер подключится, он выполнит команды, описанные в inline.
В блок inline команды передаются списком. У нас всего одна длинная команда, для удобства чтения мы записываем ее с переносами строки и передаем в heredoc-формате. Форматирование в примере выше является корректным: маркеры блока EOT для корректной работы не должны иметь отступов.
В итоге после создания виртуальной машины провижнер подключится к машине по ssh и запустит docker-контейнер ghcr.io/requarks/wiki:2.5 с приложением. В параметры подключения к кластеру БД указываем те же переменные, которые использовали при описании кластера. Хост кластера БД станет известен после его создания. Чтобы получить его в скрипте, ссылаемся на поле кластера yandex_mdb_postgresql_cluster.dbcluster.host.0.fqdn.
Единственное, что осталось учесть, — это порядок создания ресурсов. В этом нам помогут зависимости.
Зависимости
Технически возможна ситуация, когда виртуальная машина развернется раньше кластера БД, и приложение не сможет подключиться к базе. В этом случае нам хотелось бы иметь явную зависимость, ограничивающую создание виртуальных машин, пока кластер не готов к работе.
Добавим свойства depends_on в наших ресурсах. Кластер баз данных будет зависеть от ресурсов сети и подсети, а виртуальная машина — от кластера БД:
Для сервера тоже нужна подсеть, но поскольку мы уже неявно обозначили зависимость от нее через кластер БД, в блок depends_on ее можно не добавлять.
Terraform при развертывании инфраструктуры строит свой внутренний граф зависимостей на основе ссылок на поля других ресурсов. Если инфраструктура несложная (как в этом уроке), он вполне способен правильно выстроить порядок сам. Но лучше сразу привыкнуть держать зависимости под контролем.
Также этот подход добавляет прозрачности тому, что и в каком порядке происходит при конфигурации инфраструктуры.
На этом этапе у нас всё готово. Осталось выполнить terraform apply и убедиться, что все создалось и запустилось.
Создание инфраструктуры
Выполним terraform apply:
Terraform will perform the following actions:
# yandex_compute_instance.vm will be created
+ resource "yandex_compute_instance" "vm" {
...
# yandex_mdb_postgresql_cluster.dbcluster will be created
+ resource "yandex_mdb_postgresql_cluster" "dbcluster" {
...
Запустим создание инфраструктуры и проследим за порядком:
yandex_vpc_network.net: Creating...
yandex_vpc_network.net: Creation complete after 2s [id=enp49digsf8iut549fve]
yandex_vpc_subnet.subnet: Creating...
yandex_vpc_subnet.subnet: Creation complete after 1s [id=e9b0r2vjb50q1s37is8v]
yandex_mdb_postgresql_cluster.dbcluster: Creating...
yandex_mdb_postgresql_cluster.dbcluster: Still creating... [10s elapsed]
...
yandex_mdb_postgresql_cluster.dbcluster: Still creating... [6m20s elapsed]
yandex_mdb_postgresql_cluster.dbcluster: Creation complete after 6m23s [id=c9qnurf8pfd32bpmitmm]
yandex_mdb_postgresql_user.dbuser: Creating...
yandex_compute_instance.vm: Creating...
yandex_mdb_postgresql_user.dbuser: Still creating... [10s elapsed]
yandex_compute_instance.vm: Still creating... [10s elapsed]
...
andex_mdb_postgresql_user.dbuser: Creation complete after 24s [id=c9qnurf8pfd32bpmitmm:me]
yandex_mdb_postgresql_database.db: Creating...
yandex_compute_instance.vm: Still creating... [30s elapsed]
yandex_mdb_postgresql_database.db: Still creating... [10s elapsed]
yandex_compute_instance.vm: Still creating... [40s elapsed]
yandex_compute_instance.vm: Provisioning with 'remote-exec'...
yandex_compute_instance.vm (remote-exec): Connecting to remote host via SSH...
yandex_compute_instance.vm (remote-exec): Host: 51.250.1.251
yandex_compute_instance.vm (remote-exec): User: ubuntu
yandex_compute_instance.vm (remote-exec): Password: false
yandex_compute_instance.vm (remote-exec): Private key: true
yandex_compute_instance.vm (remote-exec): Certificate: false
yandex_compute_instance.vm (remote-exec): SSH Agent: true
yandex_compute_instance.vm (remote-exec): Checking Host Key: false
yandex_compute_instance.vm (remote-exec): Target Platform: unix
yandex_compute_instance.vm (remote-exec): Connected!
yandex_compute_instance.vm: Still creating... [1m0s elapsed]
yandex_compute_instance.vm (remote-exec): Unable to find image 'ghcr.io/requarks/wiki:2.5' locally
yandex_compute_instance.vm (remote-exec): 2.5: Pulling from requarks/wiki
yandex_compute_instance.vm (remote-exec): 31e352740f53: Pulling fs layer
yandex_compute_instance.vm (remote-exec): 2629b68d4311: Pulling fs layer
...
yandex_compute_instance.vm (remote-exec): Status: Downloaded newer image for ghcr.io/requarks/wiki:2.5
yandex_compute_instance.vm (remote-exec): c33a8f713d927bc0fa3f042a0d20a44b5abcc7798312ff58964d2f46664b4a17
yandex_compute_instance.vm: Creation complete after 1m23s [id=fhmdenv9loufk2m2gcj2]
Apply complete! Resources: 6 added, 0 changed, 0 destroyed.
По логу можно заметить:
- Заданный нами порядок соблюдается
- Провижнер логирует в Terraform операции, которые выполняет
- Создание сервера не считается завершенным до тех пор, пока провижнер не отработал полностью
Приложению понадобится пара минут, чтобы установить все зависимости и накатить миграции в БД. После этого мы можем зайти на внешний IP сервера и увидеть админку wiki.js, готового к работе.

Можем создать администратора и добавить пару статей в нашу новую wiki. Приложение сохранит данные в базу.
После этого мы можем полностью удалить наш сервер через интерфейс облака и повторно вызвать terraform apply. Terraform не найдет yandex_compute_instance.vm и предложит создать его заново. Развернем сервер снова и зайдем на него по новому внешнему IP, который ему выдало облако. Там мы должны увидеть ту же самую wiki и уже созданные нами статьи.
Когда закончите практику, не забудьте выполнить terraform destroy, чтобы убрать из облака всю созданную в проекте инфраструктуру.
Выводы
В этом уроке мы разобрались, как с помощью Terraform описать и поднять в облаке готовое к работе stateful-приложение. Такое решение с сервером и базой является вариантом применения подхода «неизменяемая инфраструктура» — когда мы полностью конфигурируем сервер на этапе создания. А если нужно что-то поменять в настройках — просто удаляем его и инициируем создание нового.
