SQL
Теория: Группировка по выборке
Агрегатные функции часто используются в запросах. Например, мы можем подсчитать количество курсов, на которые записался каждый пользователь.
Сначала выберем уникальных пользователей в таблице course_members:
Затем для каждого пользователя подсчитаем количество курсов. Запросы будут выглядеть так:
Проблема в том, что в нашей таблице слишком много пользователей. Писать отдельный запрос для каждого слишком долго, а еще есть вероятность кого-то пропустить.
Справиться с этой сложностью помогает группировка данных, которую мы изучим в этом уроке.
Оператор GROUP BY
Группировка данных позволяет объединить одинаковые значения в заданных полях в группы, а затем выполнять подсчеты для каждой группы.
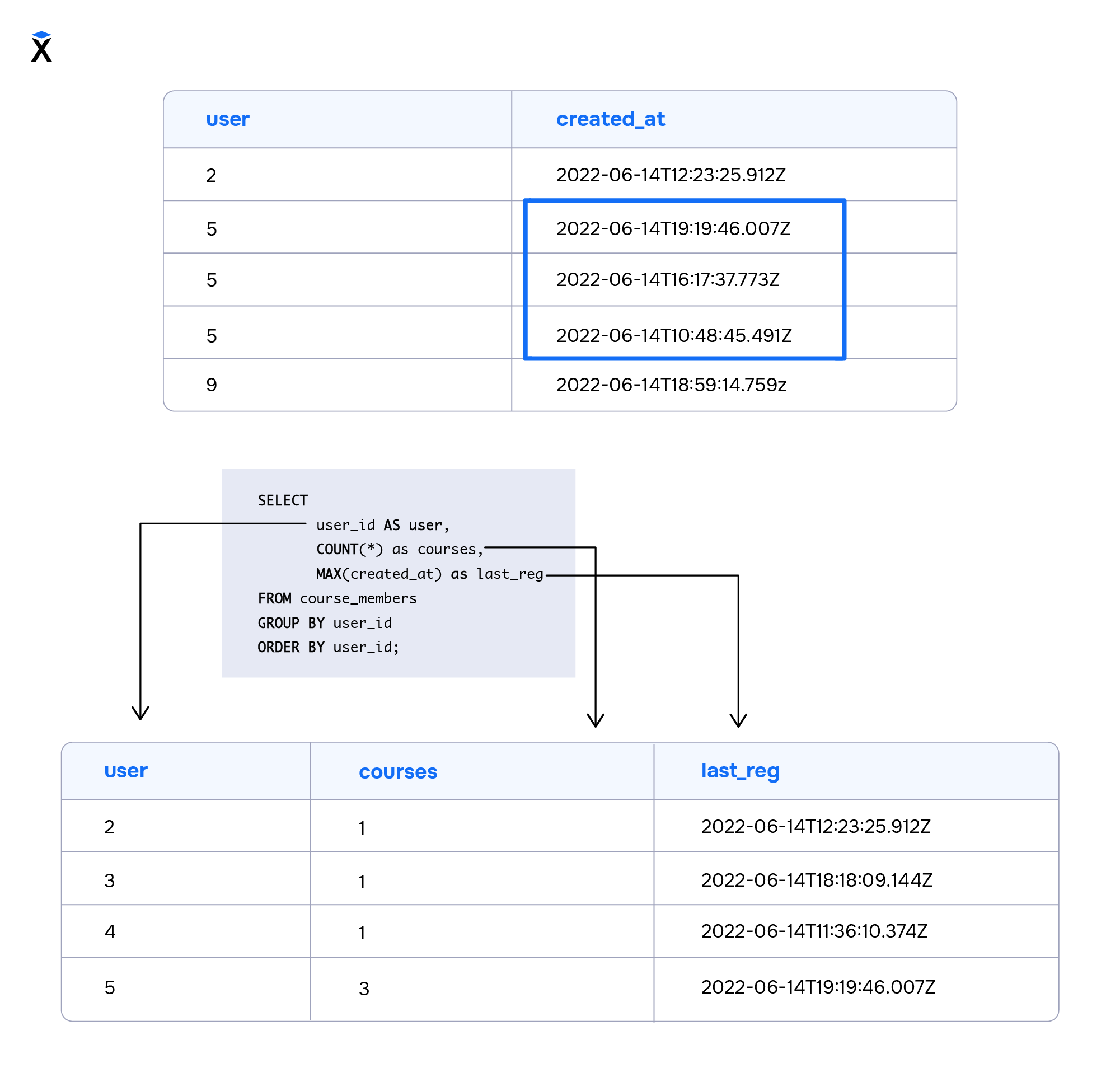
Для группировки данных существует специальный оператор GROUP BY. Запрос с подсчетом курсов каждого пользователя будет выглядеть так:
Мы могли бы создавать по отдельному запросу для каждого пользователя, но вместо этого использовали конструкцию GROUP BY user_id. В ней мы указали, что нам нужно объединить строки с одинаковыми идентификаторами user_id, вывести идентификатор и количество строк в каждой группе COUNT(*).
Для удобства мы отсортировали данные по идентификатору, но это необязательно:
Псевдонимы для столбцов
Система управления базами данных автоматически присвоила нашему второму столбцу имя count, совпадающее с именем функции. Но мы можем переименовать этот столбец, как и любой другой:
Чтобы присвоить столбцу псевдоним, нужно после его определения записать AS и указать желаемое имя. Оно должно начинаться с буквы и не должно содержать пробелов.
Как работает GROUP BY
Теперь попытаемся выполнить следующий запрос:
Запрос завершится с ошибкой:
Ошибка в том, что СУБД не понимает, что делать со столбцом created_at — либо он должен быть в конструкции GROUP BY, либо к нему надо применить агрегатную функцию.
Чтобы лучше понять работу GROUP BY, разберемся, почему запрос выше не работает.
Дело в том, что группировка обращается к записям в таблице. Она создает из них независимые группы записей, по которым проводится анализ.
При работе с группой мы можем выбрать один из двух вариантов:
- Либо вывести поле, по которому проводим группировку. Его значение будет одинаковым для группы
- Либо применить к полю какую-либо агрегатную функцию — например,
COUNT(),MAX(),MIN()илиAVG(). В этом случае СУБД будет знать, как обработать несколько разных значений.
Вернемся к примеру выше. В своем запросе мы не группируем данные по столбцу created_at — это не то, что нам нужно. Если бы мы это сделали, пришлось бы работать с группами, в которых совпадают идентификатор пользователя и дата создания.
Кроме того, мы не указали никакой агрегатной функции для этого столбца. СУБД не понимает, что именно нужно сделать с группой разных дат создания. Нужно посчитать среднее? Или взять максимальную дату?
Давайте исправим запрос. Выведем максимальное значение поля created_at для группы. Это будет дата последней регистрации пользователя на курс:
Выводы
В этом уроке мы изучили оператор GROUP BY. Теперь вы можете объединять одинаковые записи в группы и считать для этих групп агрегатные функции.
Важно помнить, что поля, которые вы будете выводить в запросе, нужно указывать в операторе GROUP BY или применять к ним агрегатную функцию.