Аналитика на SQL
Теория: Риски и опасности NULL
На практике очень редко можно столкнуться с таблицами, содержащие абсолютно чистые и полные данные. Более вероятно, что вы будете работать с таблицами, в которых некоторые значения отсутствуют. В SQL эти отсутствующие данные обозначаются как NULL. Обработка таких значений — это важный навык для аналитика, потому что неправильное управление NULL-значениями может привести к искаженным результатам и ошибочным выводам.
Чтобы попрактиковаться в работе с NULL в SQL, мы использовали нашу базу данных и составили в ней таблицу delivery, которая содержит следующие столбцы:
- id доставки (
delivery_id) - id заказа (
order_id) - дата доставки (
delivery_date) - адрес доставки (
delivery_address)

В этой таблице мы оставили пропуски в дате доставки и адресе доставки, чтобы показать, как SQL операторы могут обрабатывать эти NULL-значения.
Операторы для обработки NULL в SQL
Для начала познакомимся с оператором COALESCE. С его помощью можно выбрать первое ненулевое значение из списка. Он принимает два или более аргументов и возвращает первый аргумент, который не равен NULL. Если все аргументы равны NULL, COALESCE возвращает NULL.
Предположим, мы хотим получить адрес доставки для каждого заказа, но в некоторых случаях адрес доставки отсутствует. Для таких случаев мы можем использовать COALESCE, чтобы вместо NULL вывести строку с текстом «Адрес не указан». Вот как это можно сделать:
В этом запросе для каждого заказа из таблицы delivery мы получаем два параметра — order_id и delivery_address. Если delivery_address равен NULL, оператор COALESCE заменяет его на строку 'Адрес не указан'.

Таким образом, даже если в исходных данных есть отсутствующие значения, мы все равно получаем полезную информацию для каждого заказа.
Аналогично оператору COALESCE, мы можем использовать IFNULL — получится тот же результат. Оператор IFNULL принимает два аргумента и возвращает первый, если он не NULL. В противном случае возвращается второй аргумент.
Для приведенного примера с таблицей delivery запрос будет выглядеть так:
Результат запроса будет совпадать с результатом использования COALESCE

В SQL также есть операторы NVL, NVL2 и DECODE. Они также позволяют обрабатывать NULL-значения, но не поддерживаются в СУБД SQlite. В этом смысле надежнее всего использовать оператор COALESCE, потому что он поддерживается практически во всех известных реляционных СУБД.
Риски работы с NULL
Существует множество различных нюансов при работе с NULL значениями, которые всегда следует учитывать.
Для примера попробуем найти всех клиентов, у которых не указан возраст. Если мы используем оператор =, запрос не вернет никаких результатов, даже если в таблице есть клиенты с возрастом NULL:
SQL считает, что NULL не равно ничему, даже другому NULL. Поэтому age = NULL всегда возвращает false, и никакие строки не выбираются.
Вместо этого следует использовать оператор IS NULL:

Этот запрос вернет всех клиентов, у которых в столбце age указано значение NULL — то есть не указан возраст.
Еще следует помнить, что арифметические операции с NULL в SQL всегда возвращают NULL. Например, мы берем таблицу customers и хотим увеличить customer_id каждого клиента на единицу:
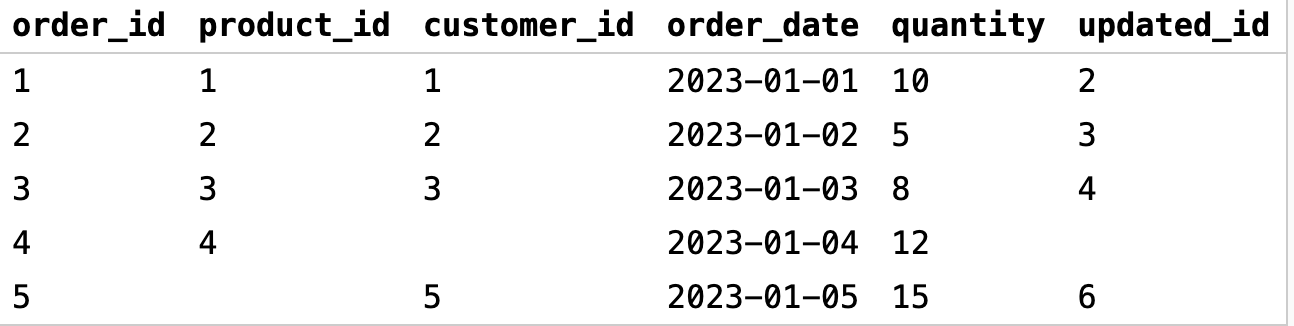
Если значение customer_id было NULL, то updated_id также будет NULL, несмотря на прибавление единицы. Это может привести к неожиданным результатам, ведь мы ожидали увеличение на единицу во всех customer_id. Чтобы с такой проблемой не сталкиваться, можно использовать COALESCE и заменить NULL на 0 перед выполнением арифметической операции:
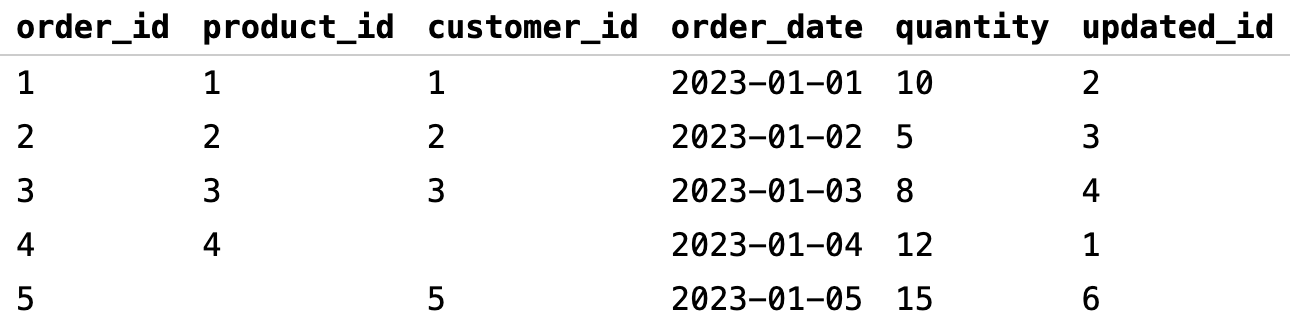
Еще один неочевидный момент — мы можем случайно нарушить связи между таблицами, если попытаемся соединить данные из двух таблиц, во внешнем ключе которых есть NULL.
Вернемся к нашей таблице orders. В ней столбец product_id является внешним ключом — то есть он ссылается на столбец product_id в другой таблице products. При этом у нас есть заказы с product_id = NULL.
Если мы попытаемся связать данные заказа с данными клиента, то заказы с product_id = NULL не свяжутся с продуктом:

В этом запросе заказы с product_id = NULL не включились в таблицу, потому что их нельзя связать с продуктами по внешнему ключу. Это может привести к потере информации в результатах запроса, если эти заказы важны для анализа.
Чтобы учесть такие заказы, можно использовать LEFT JOIN вместо INNER JOIN:

Теперь все заказы будут включены в результат, но product_name будет равен NULL для заказов, у которых product_id = NULL.
Также при работе с NULL следует помнить о нюансах, с которыми мы столкнулись на предыдущих уроках.
Например, NULL-значения могут появляться в разных местах в результате сортировки в зависимости от СУБД. В некоторых они появляются на вершине при сортировке по возрастанию, а в других — на дне. С помощью операторов NULLS LAST и NULLS FIRST мы можем указать явно, где должны располагаться значения NULL в результирующем наборе данных.
Наконец, при работе с агрегирующими функциями (например, COUNT, AVG, SUM) следует иметь в виду, что они обрабатывают NULL по-особенному. Всегда сверяйтесь с документацией функции для конкретной базы данных.
Выводы
Подведем итоги и сформулируем правила работы с NULL-значениями:
- В SQL существуют различные функции и операторы для обработки
NULLзначений, такие какCOALESCE,IFNULL,NVL,NVL2, иDECODE. Но не все из них поддерживаются во всех СУБД, поэтому важно знать и уметь использовать универсальные функции, такие какCOALESCE - Значения
NULLведут себя особым образом при выполнении запросов. Например, они не равны ничему (даже другомуNULL), их арифметические операции всегда возвращаютNULL, и они могут быть расположены в разных местах при сортировке в зависимости от СУБД. - Если столбец — это внешний ключ, то
NULL-значения в нем могут нарушать связи между таблицами и приводить к потере информации при выполненииJOIN-запросов - Агрегирующие функции (
COUNT,AVG,SUM) особенным образом обрабатываютNULL-значения, что может привести к искажению результатов агрегации

