Аналитика на SQL
Теория: Агрегация с помощью оператора COUNT
Агрегация (COUNT)
На начальном этапе исследования данных аналитику зачастую необходимо банально подсчитать количество элементов в группе или наборе данных и представить эту информацию в виде одного числа. Для решения задачи такого рода полезно начать работу с использования агрегирующей функции COUNT.
Функция COUNT называется агрегирующей, потому что она собирает или "складывает" информацию из нескольких строк данных в одно значение. Агрегирующие функции, такие как COUNT, используются для упрощения и обобщения данных, чтобы сделать их более понятными и удобными для анализа.
Считаем общее количество строк и значений столбца
Представим, что мы хотим посчитать общее количество продаж из нашей базы данных:
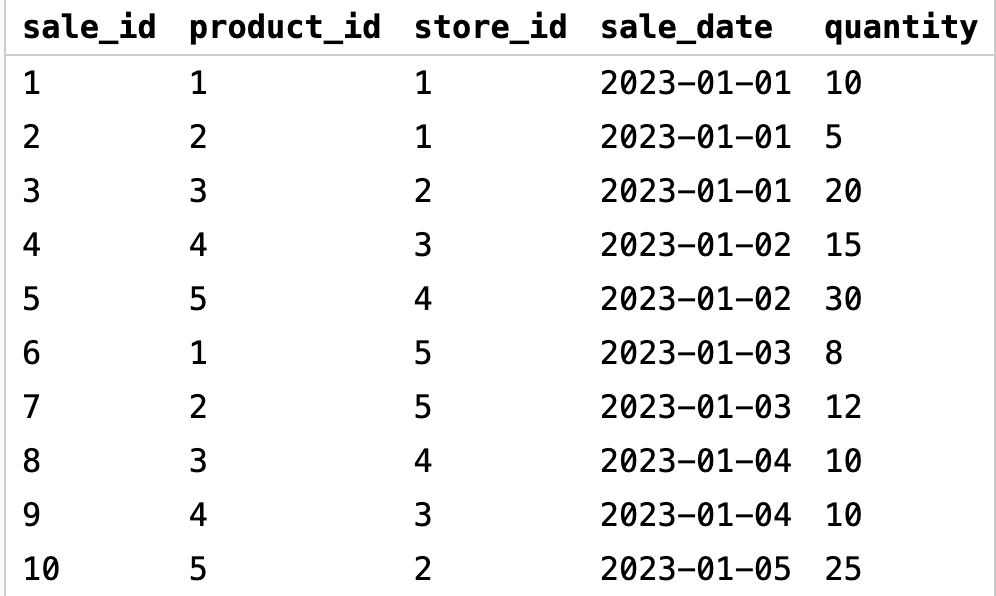
Для этого выполним следующий запрос:
Получим такой результат:

В запросе выше мы передали функцию COUNT со звездочкой в качестве аргумента. Так мы подсчитываем количество всех строк в таблице, независимо от их значений. Поэтому в расчет берутся столбцы и с определенными значениями, и со значением NULL.
А теперь попробуем заменить звездочку на название какого-либо столбца из таблицы:
В этом запросе мы использовали функцию COUNT(название_столбца). Результат получился тот же самый:

В большинстве случаев COUNT(*) и COUNT(название_столбца) дадут одинаковые результаты, но работают они по-разному.
Разница между COUNT(*) и COUNT(название_столбца) заключается в том, как они обрабатывают NULL — нулевые значения:
- Функция
COUNT(*)подсчитывает все строки в выборке. Для нее не важно, есть строки с нулевым значением или нет - Функция
COUNT(название_столбца)подсчитывает только строки со значениями, не включая нулевые значения. Если значение столбца равноNULL, строка с ним не войдет в общее количество
Если столбец не содержит строки с нулевым значением, то функции дадут одинаковые результаты. Но если нулевые значения все таки есть, то функция COUNT(название_столбца) выдаст меньше строк, чем COUNT(*) — строки с NULL не зачтутся.
Считаем количество уникальных значений
С помощью функций COUNT и DISTINCT можно решать аналитические задачи, связанные с подсчетом уникальных значений в столбцах.
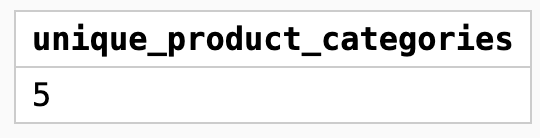
Для примера представим, что нам нужно узнать количество уникальных категорий товаров в нашей базе. Напишем такой запрос:
Получим такой результат:

Если мы хотим выбрать уникальные комбинации значений из нескольких столбцов, можно использовать DISTINCT с несколькими колонками.
Например, подсчитаем уникальные комбинации продуктов и их категорий:
Здесь результат будет таким:
В SQLite, MySQL и некоторых других СУБД нельзя напрямую использовать COUNT(DISTINCT название_столбца1, название_столбца2). Вместо этого можно воспользоваться конкатенацией строк. Для этого мы:
- Сначала используем функцию
||, чтобы объединить значения из нескольких столбцов - А затем применяем функцию
COUNT(DISTINCT ...)
Выводы
В этом уроке мы рассмотрели функцию COUNT и выяснили, как она помогает аналитикам в работе. Кратко подведем итоги:
COUNT— это агрегирующая функция, которая подсчитывает количество элементов в группе или наборе данных- Можно использовать
COUNT(*)илиCOUNT(название_столбца). Эти две функции по-разному работают с нулевыми значениями - Посчитать уникальные значения в столбцах можно с помощью функций
COUNTиDISTINCT - Те же функции помогают посчитать уникальные комбинации значений из нескольких столбцов с использованием конкатенации строк
Умение работать с функцией COUNT помогает аналитику проводить более сложный анализ данных, извлекать уникальные характеристики и обобщать информацию.

