Python: Pandas
Теория: Использование Pandas для работы с табличными данными
В библиотеке Pandas есть инструменты под разные задачи. Для анализа табличных данных существует определенная последовательность шагов и используемых решений. Их можно встретить практически в любом проекте. В этом уроке мы разберем, как решать определенные задачи с использованием методов библиотеки Pandas.
Шаги для работы с библиотекой Pandas
Аналитику важно уметь пользоваться инструментами библиотеки Pandas для решения следующих задач:
- Чтение данных из файловой системы
- Первичный анализ данных
- Трансформация данных: исправление пропусков и некорректных значений, извлечение из данных аналитических показателей
- Запись результатов обратно в файловую систему
Разберем каждую ситуацию подробнее.
Чтение данных из файловой системы
Обычно для хранения табличных данных используют формат csv. Также могут встречаться форматы xls и json. Для чтения данных из файловой системы в Pandas есть набор методов под разные типы данных.
Все методы первым параметром ожидают путь к файлу. Можно конфигурировать различные сценарии чтения. В нашем случае мы указываем, что колонка, в которой хранятся значения индексов строк, идет первой по счету. Напомним, что в программировании счет начинается с нуля:
Для работы с табличными данными в Pandas реализован особый тип данных — DataFrame. Это не просто массив хранимых значений, а структура с особой формой хранения индексов строк и столбцов.
На практике ошибка в процессе чтения может и не возникнуть. При этом данные могут считаться некорректно или вовсе не быть прочитанными. После чтения данных полезно провести проверку. Для просмотра достаточно воспользоваться методом head(). Он выводит название столбцов и значения первых пяти строк:
В этом примере мы считали данные кликов кнопки покупки для разных магазинов за некоторый период времени.
Чтобы посмотреть последние строки таблицы, воспользуемся методом tail():
Первичный анализ данных
Для первичного анализа данных используется метод info(). Он показывает количество считанных строк, непустых значений в каждом из столбцов и тип хранимых в них данных:
В таблице тип каждой колонки данных указан в столбце Dtype. В данном случае все колонки типа float64 — числа с плавающей запятой. В столбце Non-Null Count указано количество непустых ячеек в каждой колонке. По этим значениям можно судить о наличии пропусков в данных. В колонке SHOP1 26 непустых значений из 28, получается, в ней два пропуска.
Чтобы получить статистические показатели числовых значений, используем метод describe(). С его помощью можно по каждому столбцу увидеть средние и отклонения от них, минимумы и максимумы, персентильные значения:
Иногда нужно проанализировать наличие тех или иных столбцов. Но их может быть довольно много. Чтобы получить названия всех столбцов, нужно обратиться к атрибуту columns датафрейма:
Этот атрибут можно изменять. Так можно переименовывать столбцы, если это необходимо:
Наглядное представление данных может упростить их анализ. В Pandas встроены методы визуализации данных на базе библиотеки Matplotlib. Чтобы визуализировать изменения значений в определенном столбце, воспользуемся методом plot():
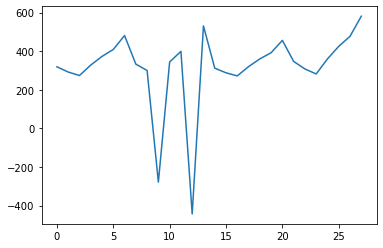
На рисунке видны выбросы в данных. Нужно понять причины их возникновения и постараться исправить.
Трансформация данных
У библиотеки Pandas много функций, чтобы обрабатывать и трансформировать данные. Часто используются заполнения пропусков и исправление ошибок. В нашем примере есть пропущенные и отрицательные значения. Для дальнейшего анализа они могут нам помешать, поэтому исправим это:
Подготовка данных выполнена. Добавим аналитической информации: столбец со средними показателями кликов за день:
Запись результатов в файловую систему
Теперь нам нужно сохранить результаты. Форматы файлов для хранения также могут быть различными. При этом интерфейс методов один и тот же:
Выводы
Для работы с данными аналитики придерживаются определенной последовательности действий. Она включает в себя чтение данных, их первичный анализ, исправление некорректных значений, статистический анализ и запись полученных результатов. Без них не обходится практически ни один проект, поэтому важно уметь работать с инструментами, которые позволяют их выполнять. Библиотека Pandas предоставляет такие методы. В этом уроке мы разобрали случаи их использования на практических примерах.

