Python: Списки
Теория: Стек
Тема алгоритмов не существует сама по себе. Важно не только уметь составлять правильный алгоритм решения, но не менее важно использовать для работы с данными правильную структуру.
Структура данных — это конкретный способ хранения и организации данных. В зависимости от решаемых задач удобным оказывается либо один способ организации данных, либо другой. Как минимум одну структуру данных вы уже знаете достаточно хорошо — это список. С точки зрения организации список представляет собой совокупность элементов, к которым имеется индексированный доступ (доступ по индексу), а вот с точки зрения физического хранения в памяти — все сложнее. Списки, частный случай массивов, массивы бывают разные и внутри языка реализуются тоже по-разному.
Кроме списков, существует множество других структур данных: хеш-таблицы, деревья, графы, стек, очередь и другие. Использование структуры данных, подходящей под решаемую задачу, позволяет кардинально упростить код, устраняя запутанную логику.
Некоторые из перечисленных структур данных мы рассмотрим в процессе прохождения курсов и проектов. Знания о других вам нужно будет подтянуть самостоятельно из книг. В любом случае алгоритмы и структуры данных (без фанатизма) составляют базу, на которую нанизывается все остальное в разработке.
Стоит разделять три понятия:
- Структура данных
- Конкретный тип данных (или просто "тип данных")
- Абстрактный тип данных (АТД)
Со структурой данных все понятно, выше было определение. С типом данных тоже все просто. Например, числа в Python — это тип данных. Понятие «тип данных» всегда привязано к конкретному языку и может быть абсолютно чем угодно в зависимости от предпочтений разработчиков языка. Другими словами, если бы разработчики Python решили, что числа надо назвать типом данных String, то никто бы им этого не запретил, несмотря на абсурдность такого имени для чисел.
А вот абстрактные типы данных — теоретическое понятие. АТД целиком и полностью определяется набором операций, которые можно выполнять над ним. АТД абстрактный потому, что он ничего не говорит о способе хранения и существует лишь на бумаге и в головах. А вот уже в конкретных языках существуют конкретные типы, реализующие АТД. АТД нередко путают с понятием «структура данных», более того, часто структуры данных и АТД имеют одно и то же название. Сильно погружаться в эти дебри не нужно, достаточно иметь общее представление.
В этом уроке мы разберем один из самых простых и важных абстрактных типов данных – стек (stack, переводится как стопка).
Стек
Стек — упорядоченная коллекция элементов, в которой добавление новых и удаление старых элементов всегда происходит с одного конца коллекции. Обычно его называют вершиной стека.
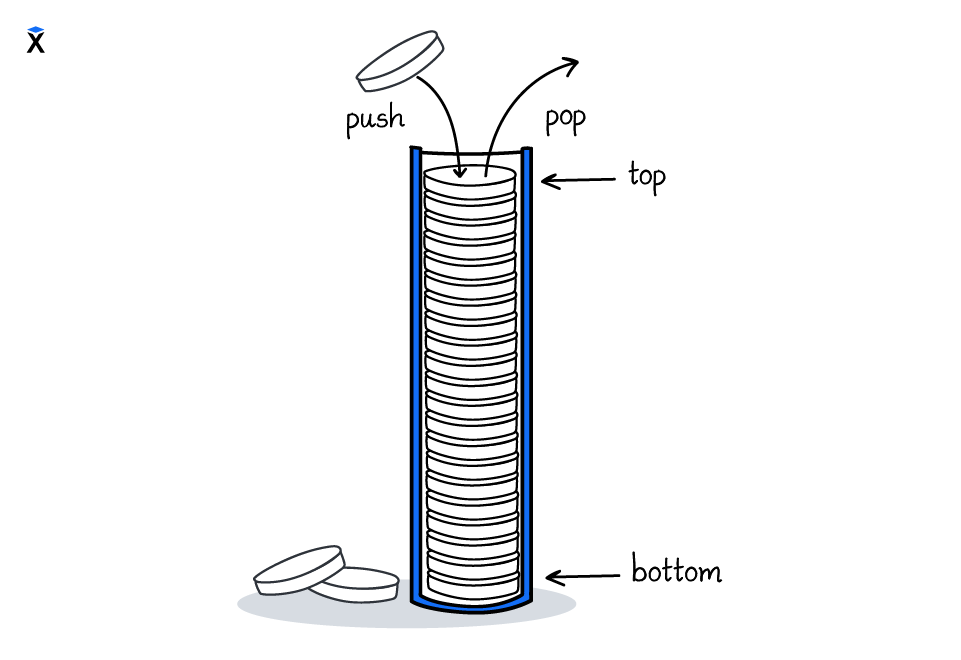
У стека есть аналоги из реальной жизни. Например, туба с монетами. Монеты добавляются в тубу только друг за другом. Извлекаются тоже, только в обратном порядке. Последняя монета достается из тубы первой.
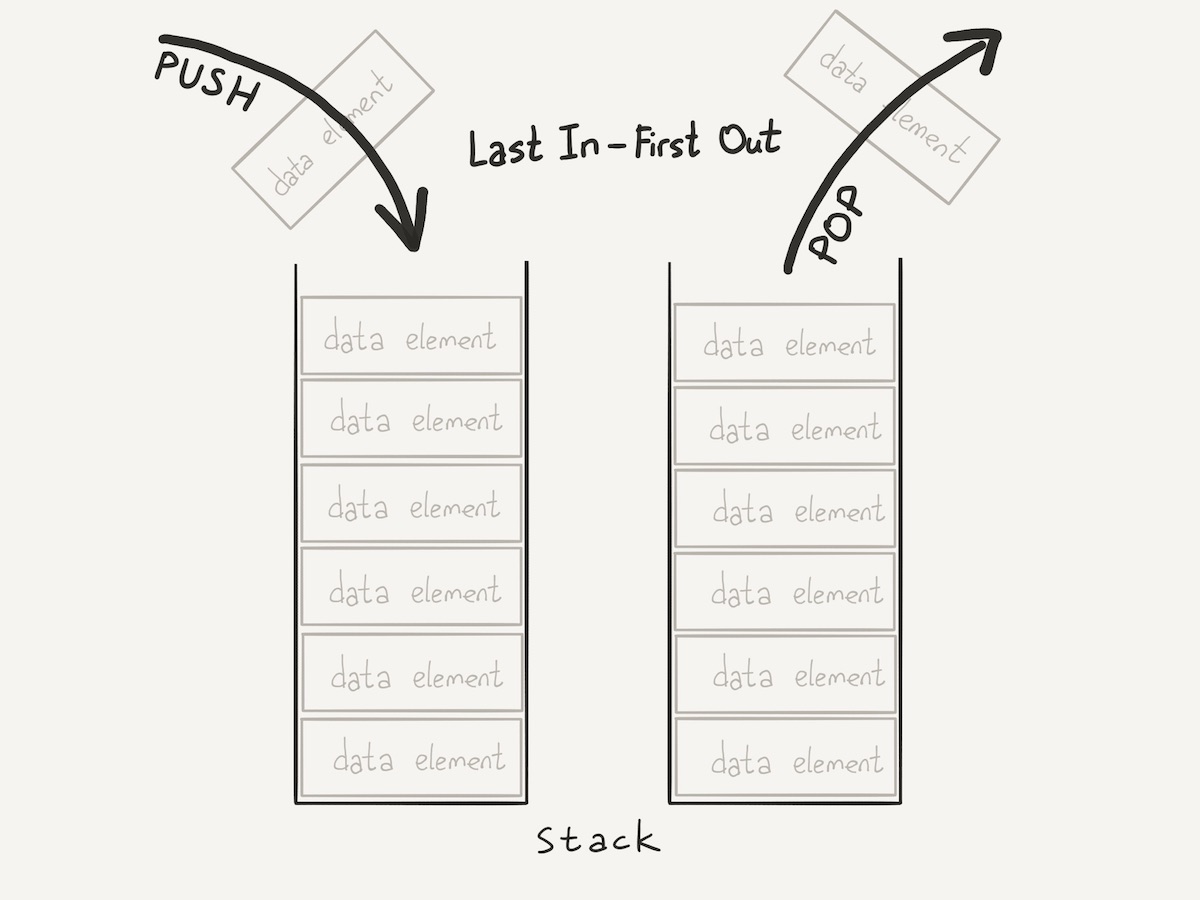
Практически любая стопка может рассматриваться как стек. Если не применять грубую физическую силу, то со стопками мы работаем двумя способами. Либо кладем новый элемент (например, книгу) на верхушку стопки, либо снимаем элемент с верхушки. Поэтому стек еще называют "Last In First Out" (LIFO), то есть "последним зашел, первым вышел".
Перед тем, как разбирать конкретную задачу, посмотрим на роль, которую играет стек в программировании. Вспомните, как исполняется любая программа. Одни функции вызывают другие, которые, в свою очередь, вызывают третьи, и так далее. После того как выполнение заходит в самую глубокую функцию, та возвращает значение, и начинается обратный процесс. Сначала идет выход из наиболее глубоких функций, затем из тех, что уровнем выше, и так далее до тех пор, пока не дойдет до самой внешней функции. Вызов функций — не что иное, как добавление элемента в стек, а возврат – извлечение из стека. Именно так все устроено на аппаратном уровне. К тому же, если в процессе выполнения программы происходит ошибка, то ее вывод часто называют Stack Trace (трассировка стека).
Другой пример, связанный с программированием — кнопка "назад" в браузере. История посещений представляет собой стек, каждый новый переход по ссылке добавляет ее в историю, а кнопка «назад» извлекает из стека последний элемент.
Работа со стеком включает в себя следующие операции:
- Добавить в стек (push)
- Взять из стека (pop)
- Вернуть элемент с вершины стека без удаления (peek_back)
- Проверить на пустоту (is_empty)
- Вернуть размер (size)
Первые две – базовые, остальные нужны время от времени. В Python стек можно создать на основе списков. Для этого используются методы append(), pop() и функция len().
Обратите внимание, что методы pop() и append() изменяют исходный список. pop() не только изменяет его, но и возвращает элемент, снятый со стека.
Рассмотрим задачку, решение которой тривиально при использовании стека. Кстати, ее нередко задают на собеседованиях, чтобы убедиться, хорошо ли вы знаете базовые структуры данных.
Задача:
Необходимо реализовать функцию, которая проверяет, что парные скобки сбалансированы. То есть каждая открывающая скобка имеет закрывающую: (), ((()())). А вот примеры несбалансированных скобок: (, ((), )(. Для проверки баланса недостаточно считать количество, важен так же порядок в котором они идут.
У этой задачи есть простое решение и без стека, но стек тоже хорошо подходит (и даже нагляднее)
Решение со стеком выглядит так:
- Если перед нами открывающий элемент, то заносим его в стек
- Если закрывающий, то достаем из стека элемент (очевидно, последний добавленный). Если стек пустой, то есть в нем нет открывающих скобок, значит выражение не соответствует требуемому формату.
- Если мы дошли до конца строки и стек пустой, то все хорошо. Если в стеке остались элементы, то проверка не прошла. Такое может быть, если в начале строки были открывающие элементы, но в конце не было закрывающих.
Разберем его построчно:
Предположим, что на вход функции попала следующая строка: ((). Ниже описание ключевых шагов при выполнении функции проверки:
- Первая скобка
(заносится в стек, так как она открывающая - Следующая скобка
(также заносится в стек по той же самой причине - Последняя
)является закрывающей, из стека извлекается последняя добавленная скобка - В стеке остался один элемент, значит баланса нет
Семантика
Может возникнуть соблазн использовать эти функции в повседневной практике. Например, чтобы извлечь из списка последний элемент. Несмотря на то, что метод pop() действительно позволяет это сделать, такой вариант использования крайне нежелателен по нескольким причинам:
-
Побочный эффект данной операции — изменение исходного списка. Даже если список потом не используется, такой код вносит потенциальные проблемы и заставляет его переписывать в будущем.
-
Нарушается семантика. Инструменты нужно использовать по назначению, иначе рождается код, который декларирует одно, но в реальности делает другое. Любой опытный программист, который видит
pop()сразу считает, что список в данной части программы используется как стек. Если это не так, то понадобятся дополнительные умственные усилия для понимания происходящего.
Для извлечения последнего элемента лучше использовать получение элемента по индексу.


