Python: Cловари и множества
Теория: Хеш-таблицы
Ассоциативный массив — абстрактный тип данных, с помощью которого хранятся пары «ключ-значение». В разных языках ему соответствуют разные типы данных. В Python — это Dictionary, в других языках:
- Ruby — Hash
- Lua — Table
- JavaScript — Object
- Elixir/Java — Map
Ассоциативные массивы популярны в прикладном программировании. С их помощью удобно представлять составные данные, содержащие множество различных параметров.
В обычном индексированном массиве значения расположены по индексам, а значит его можно положить в память «как есть». С ассоциативными массивами все работает по-другому. У них нет индексов, которые бы могли определить порядок — значит, и нет простого способа добраться до значений.
Для реализации ассоциативных массивов часто используют специальную структуру данных — хеш-таблицу.
Хеш-таблица позволяет организовать данные ассоциативного массива удобным для хранения способом. Для этого хеш-таблица использует индексированный массив и функцию для хеширования ключей. При этом хеш-таблица — это не просто способ размещать данные в памяти, она включает в себя логику.
В этом уроке мы подробнее поговорим о хеш-таблицах и узнаем, как ассоциативные массивы устроены внутри. Вы поймете, сколько разных процессов происходит в программе, когда мы выполняем подобный простой код:
Что такое хеширование
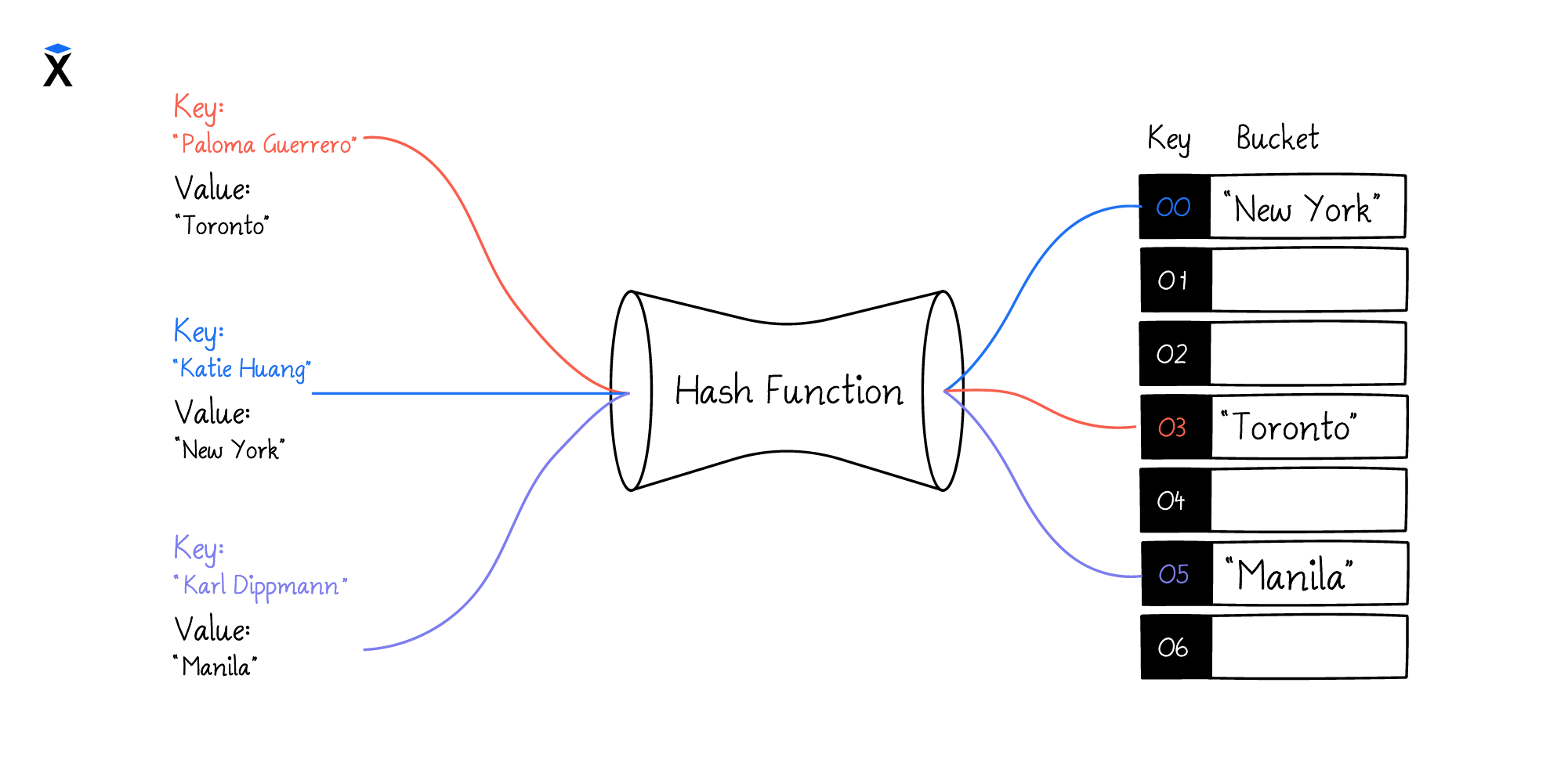
Любая операция внутри хеш-таблицы начинается с того, что ключ каким-то образом преобразуется в индекс обычного массива. Для получения индекса из ключа нужно выполнить два действия:
- Найти хеш, то есть хешировать ключ
- Привести ключ к индексу — например, через остаток от деления
Хеширование — операция, которая преобразует любые входные данные в строку или число фиксированной длины. Функция, реализующая алгоритм преобразования, называется «хеш-функцией». При этом результат хеширования называют «хешем» или «хеш-суммой».
Наиболее известны CRC32, MD5, SHA и много других типов хеширования:
С хешированием мы встречаемся в разработке часто. Например, идентификатор коммита в git 0481e0692e2501192d67d7da506c6e70ba41e913 — это хеш, полученный в результате хеширования данных коммита.
При записи в хеш-таблицу сначала нужно получить хеш. Затем его можно преобразовать в индекс массива — например, вычислить остаток от деления:
Как хеширование работает изнутри
Рассмотрим, как работает добавление нового значения в ассоциативный массив. Напомним, в Python он представлен типом данных Dictionary. Напишем такой код:
Такой простой код запускает целый сложный процесс. Для простоты рассмотрим его на Python, хотя в реальности все это происходит на более низком уровне. Опишем процесс хеширования без деталей и с упрощениями.
-
Мы создаем ассоциативный массив. Внутри интерпретатора происходит инициализация индексированного массива:
-
Далее мы присваиваем значение:
-
Затем интерпретатор хеширует ключ. Результатом хеширования становится число:
-
Далее интерпретатор берет число из предыдущего шага и преобразует его в индекс массива:
-
В конце интерпретатор ищет по индексу значение внутреннего индексированного массива и записывает его в еще один массив. Первым элементом нового массива становится ключ
'key', а вторым — значение'value':
Теперь посмотрим, как работает чтение данных:
Разберем, как этот код работает изнутри.
-
Интерпретатор хеширует ключ. Результатом хеширования становится число:
-
Число, полученное на предыдущем шаге, преобразуется в индекс массива:
-
Если индекс существует, то интерпретатор извлекает массив и возвращает его наружу:
Коллизии
Ключом в ассоциативном массиве может быть абсолютно любая строка, любой длины и содержания. Но здесь есть одно противоречие:
- Все возможные ключи — это бесконечное множество
- В качестве результата хеш-функция выдает строку фиксированной длины, то есть все выходные значения — это конечное множество
Из этого факта следует, что не для всех входных данных найдется уникальный хеш. На каком-то этапе могут появиться дубли: под одним хешем будут лежать несколько разных значений.
Такую ситуацию принято называть коллизией. Есть несколько способов разрешения коллизий. Каждому способу соответствует свой тип хеш-таблицы:
Простейший способ разрешения коллизий — это открытая адресация. Она предполагает последовательное перемещение по слотам хеш-таблицы в поисках первого свободного слота, куда значение будет записано.
В примере выше открытая адресация сработает так: интерпретатор возьмет второе значение и проверит для него хеш 1938556050. Если хеш занят, то интерпретатор попробует проверить хеш 1938556051. Так он будет продвигаться до первого незанятого хеша.
Коллизии не так редки, как может показаться. Вы можете убедиться в этом сами, если изучите парадокс дней рождений.


