PHP: Массивы
Теория: Массивы в памяти компьютера
В работе с PHP и другими высокоуровневыми языками позволительно не знать устройство массивов для решения повседневных задач. С другой стороны, подобное понимание делает код менее магическим и дает возможность заглянуть чуть дальше.
Массивы в языке C
Реальные массивы лучше всего рассматривать на языке C (читается как «си»). С одной стороны, язык C достаточно простой и понятный, а с другой — он очень близок к железу и не скрывает от нас практически ничего. Когда мы говорим о строках, числах и других примитивных типах данных, на интуитивном уровне все довольно понятно. Под каждое значение выделяется некоторый объем памяти в соответствии с типом, в которой хранится само значение.
А как должна выделяться память под хранение массива? Что такое массив в памяти? На уровне хранения, понятия «массив» не существует. Массив представляется цельным куском памяти, размер которого вычисляется так:
Из этого утверждения есть два интересных вывода:
- Размер массива — это фиксированная величина. Динамические массивы, с которыми мы имеем дело во многих языках, реализованы внутри языка, а не на уровне железа
- Все элементы массива имеют один тип и занимают одно и то же количество памяти. Благодаря этому мы можем просто применить формулу выше и получить адрес ячейки, в которой лежит нужный нам элемент. Именно это происходит при обращении к элементу массива под определенным индексом
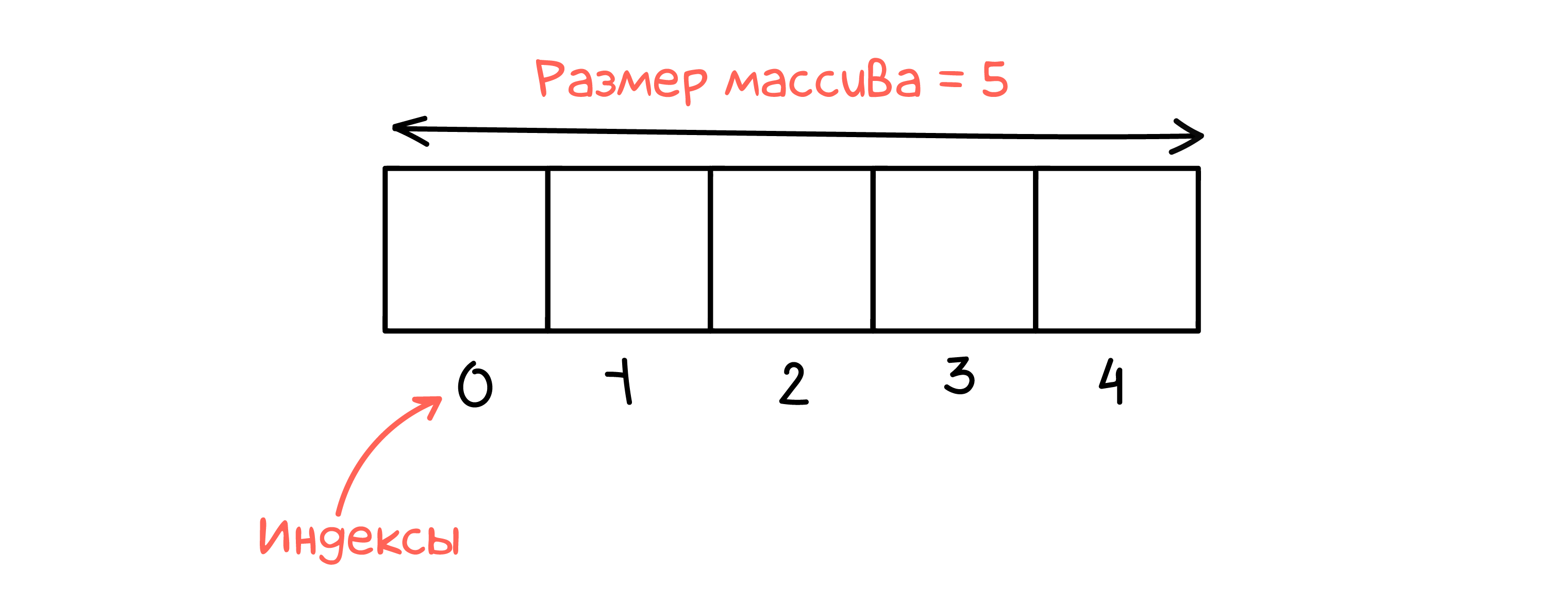
Фактически, индекс в массиве — это смещение относительно начала куска памяти, содержащего данные массива. Адрес, по которому расположен элемент под конкретным индексом, рассчитывается так:
Начальный адрес — это адрес ячейки памяти, начиная с которой размещается массив. Он формируется во время выделения памяти под массив.
Рассмотрим пример на языке C:
Если предположить, что тип int занимает в памяти 2 байта (зависит от архитектуры), то адрес элемента с индексом 3 вычисляется так: начальный адрес + 3 * 2. Для индекса 1 – начальный адрес + 1 * 2.
В такой формуле расчета адреса есть ровно один способ физически разместить данные в начале доступной памяти – использовать нулевой индекс: начальный адрес + 0 * размер элемента конкретного типа = начальный адрес.
Теперь должно быть понятно, почему индексы в массиве начинаются с нуля. В этом случае ноль означает отсутствие смещения.
Но не все данные имеют одинаковый размер. Как будет храниться массив строк? Строки ведь имеют разную длину — значит, они требуют разное количество памяти для своего хранения.
Один из способов сохранить строки в массиве на языке C – создать массив массивов. Здесь нужно понимать, что любая строка в C — это массив символов. Вложенные массивы обязательно должны быть одного размера, невозможно обойти физические ограничения массивов. Хитрость в том, что этот размер должен быть достаточно большой, чтобы туда поместились необходимые строки:
Безопасность
В высокоуровневых языках код защищен от выхода за границу массива. Но в языке C выход за границу не приводит к ошибкам.
Для примера представим, что мы обратились к элементу, индекс которого находится за пределами массива. Такое обращение вернет данные, которые лежат в той самой области памяти, куда мы попросили обратиться в соответствие с формулой выше. Чем окажутся эти данные? Никому не известно. Они будут проинтерпретированы в соответствие с типом массива. Если массив имеет тип int, то вернется число.
Из-за отсутствия какой-либо защиты, выход за границу массива активно эксплуатируется хакерами для взлома программ.
Массивы в динамических языках
В PHP, JavaScript и других динамических языках устройство массивов значительно сложнее, чем в C, потому что типы данных вычисляются автоматически во время выполнения кода. Массив в такой среде не может работать так же, как в C. Неизвестно, данные каких типов окажутся внутри в процессе работы.
Массивы в таких языках содержат не сами данные, а ссылки на них (то есть адреса в памяти). Тогда становится не так важно, что хранить. Любое значение в массиве – адрес, имеющий одинаковый размер независимо от данных, на которые он указывает. Такой подход делает массивы гибкими, но более медленными.
Кроме того, массивы в динамических языках тоже динамические — их размер может увеличиваться или уменьшаться в процессе работы программы. Технически это работает так: если ссылки (помним, что данные там не хранятся) в массив не помещаются, то интерпретатор внутри себя создает новый массив большего размера (обычно в два раза) и переносит все ссылки туда. Динамические массивы очень упрощают процесс разработки, но за это тоже приходится платить скоростью.

