JS: DOM API
Теория: DOM
Чтобы работать с JavaScript в браузерах, очень важно понимать, как они работают, хотя бы в общих чертах. Давайте возьмем для примера страницу и рассмотрим основные шаги, которые выполняет браузер для ее отображения:
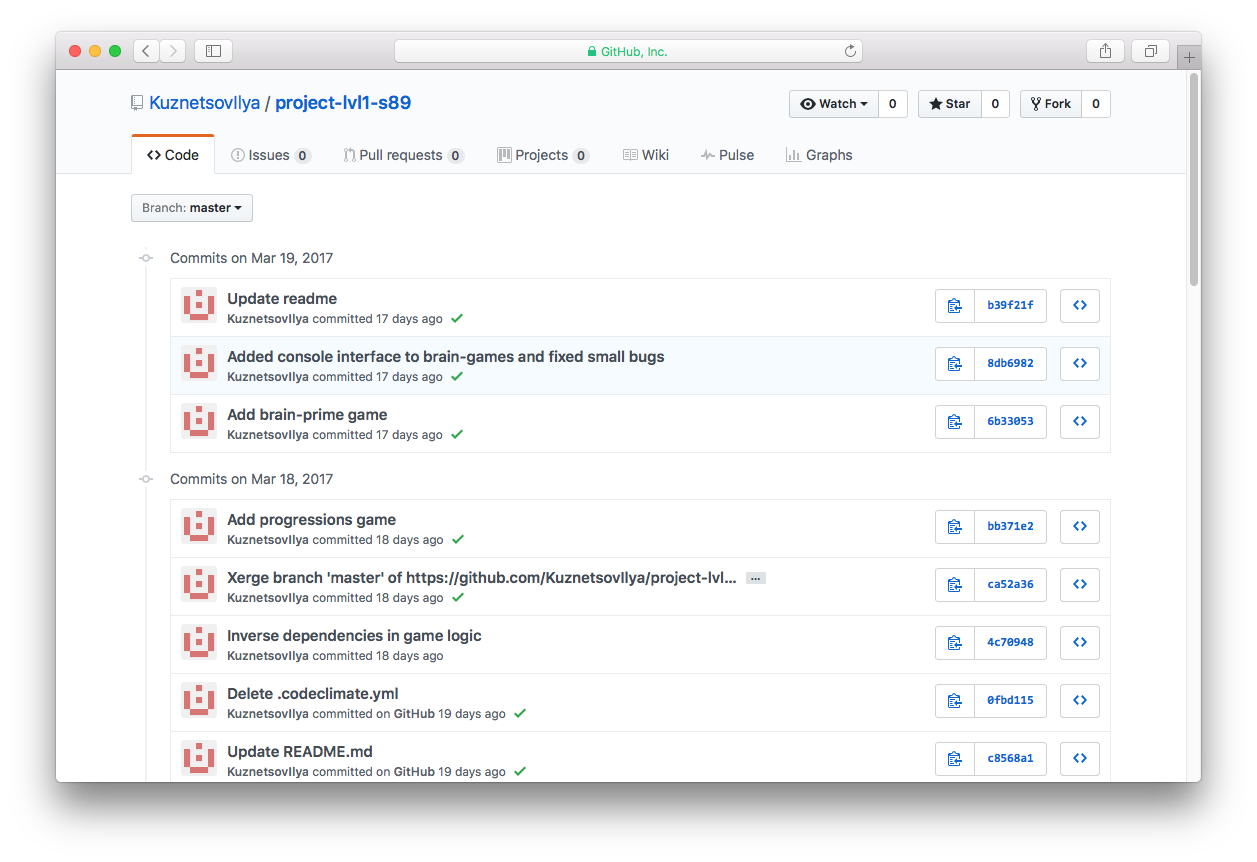
В общих чертах процесс отображения страницы выглядит так:
-
Браузер узнает адрес страницы с помощью DNS, а затем делает запрос на сервер:
Сервер присылает в ответ HTML-код.
-
Браузер получает HTML-код, анализирует его и формирует внутреннюю структуру, называемую DOM-дерево.
-
После этого браузер использует это дерево для физического рендеринга страницы, которую мы рассматриваем:
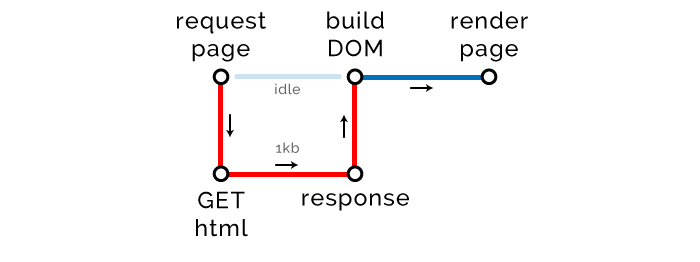
Что такое дерево DOM? Зачем оно нам нужно для создания страницы, если у нас есть HTML? Дело в том, что HTML — это просто текст. Использовать его напрямую крайне неудобно. Фактически, это невозможно.
Гораздо проще создать на его основе объект, который будет соответствовать структуре самого HTML, а затем использовать его для генерации страницы. Таким объектом и является DOM-дерево.
Слово дерево используется здесь неспроста. HTML-файл имеет древовидную структуру. Он состоит из тегов, вложенных в другие теги, которые вложены в другие теги, и так далее.
Поэтому и получившийся объект имеет такую же, древовидную структуру:
Что-то подобное происходит с исходным кодом программ JavaScript. Для интерпретатора текст неудобен. Поэтому код внутри JavaScript сначала превращается в AST (Абстрактное Синтаксическое Дерево), которое уже затем используется для запуска.
Браузер формирует DOM-дерево где-то внутри себя, но при этом он предоставляет механизм для создания DOM-дерева прямо из JavaScript:
Полученный выше объект имеет структуру, которая будет одинаковой во всех браузерах и других программах, работающих с HTML. Именно поэтому он содержит приставку DOM.
Объектная модель документа (Document Object Model) — это независимый от платформы и языка формат, который позволяет программам и скриптам получать доступ к содержимому HTML-документов, а также изменять их содержимое, структуру и дизайн.
Благодаря этому стандарту мы можем написать одну версию кода для всех браузеров. Иначе каждый браузер делал бы то, что ему хочется, и нам пришлось бы писать код для каждого браузера отдельно из-за их несовместимости.
Но все же некоторые различия есть. Браузеры развиваются с разной скоростью и не всегда успевают за изменениями в стандарте DOM. Поэтому программистам приходится ждать, пока новые функции появятся в большинстве браузеров, прежде чем использовать их.
В следующих уроках мы обсудим, как современные разработчики решают эти проблемы с помощью полифилов.
DOM-дерево текущей страницы доступно в JavaScript в виде объекта document, который наполнен множеством методов для работы с этим деревом в соответствии со спецификацией DOM.
Браузер сразу отображает любые изменения на странице:
Восстановление
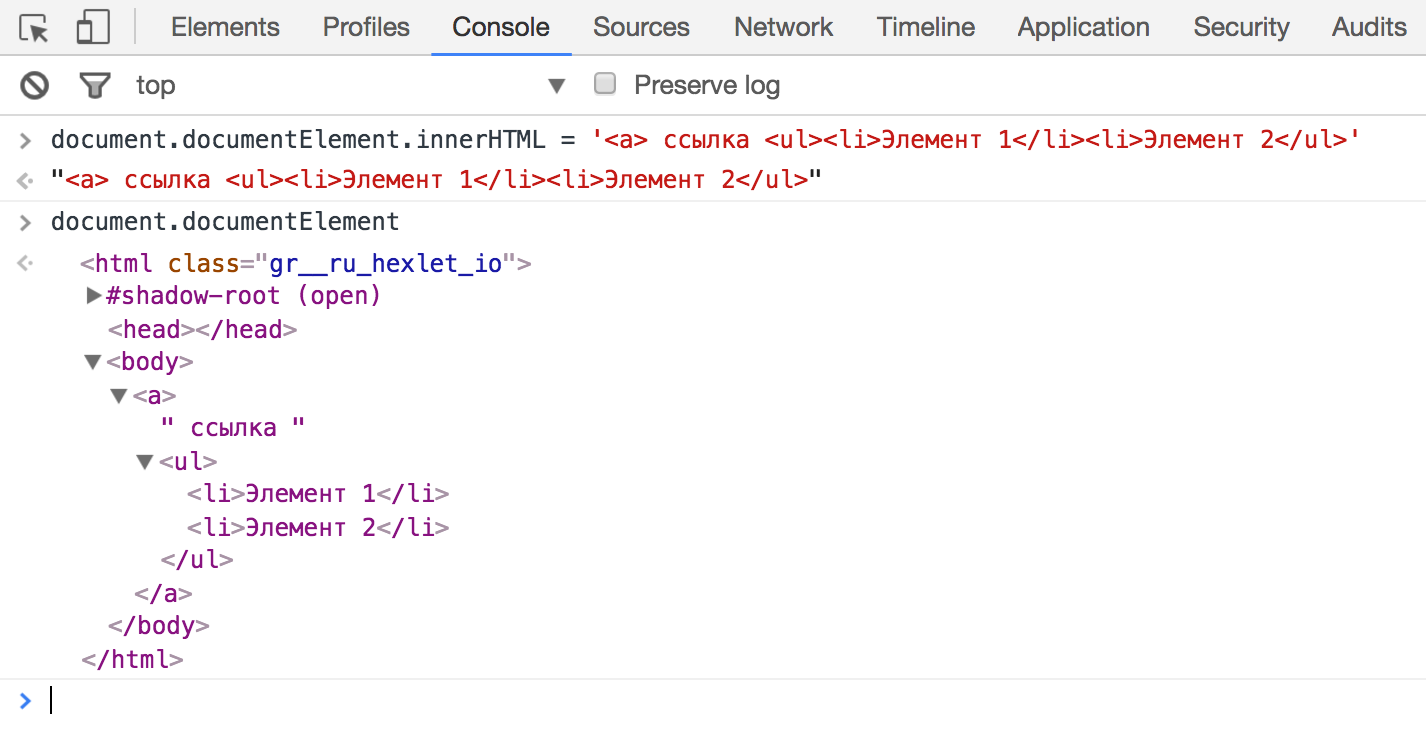
Если передать браузеру ошибочный HTML с незакрытыми тегами, нарушенной вложенностью и другими проблемами, то никаких сообщений об ошибках не будет. Браузер примет этот HTML и отобразит что-то на экране.
Вам может не понравиться результат, но все сработает:
Браузер восстанавливает структуру документа согласно некоторым очень хитрым правилам. По-другому его теоретически невозможно было бы обработать. Но есть и другая причина: даже если сам HTML корректен, когда мы создаем дерево DOM, браузер добавляет некоторые узлы дерева, представленные тегами HTML.
Вы могли этого не заметить, но стандарт требует, чтобы они там были. Например, <tbody> добавляется в таблицы, и неважно, был он в исходном HTML или нет. Другой пример, в котором добавляется список, браузер автоматически создает корневой элемент <body>:
DOM открывает практически безграничные возможности для изменения страниц. Все библиотеки (jquery и другие) и фреймворки (angular, react) манипулируют DOM. Это основа, вокруг которой строится все во фронтенд-разработке.



