JS: DOM API
Теория: Навигация по DOM-дереву
Знакомство с DOM-деревом проще всего начать с изучения структуры этого дерева.
Если коротко, DOM-дерево состоит из узлов (нод, node). Вместе узлы образуют иерархию, аналогичную HTML. При этом узлы делятся на два типа:
- Листовые — не содержат внутри себя других узлов
- Внутренние – у них есть узлы
Чаще всего конкретные узлы описывают конкретные теги из HTML и содержат их атрибуты внутри себя. У узлов есть тип, который определяет набор свойств и методов узла. В этом уроке мы с ними познакомимся.
Корневой элемент в DOM-дереве соответствует тегу <html>. Доступ к нему можно получить так:
Теги <body> и <head> всегда присутствуют внутри документа, поэтому можно вынести их на уровень объекта document для более простого доступа:
По дереву можно не только спускаться, но и подниматься:
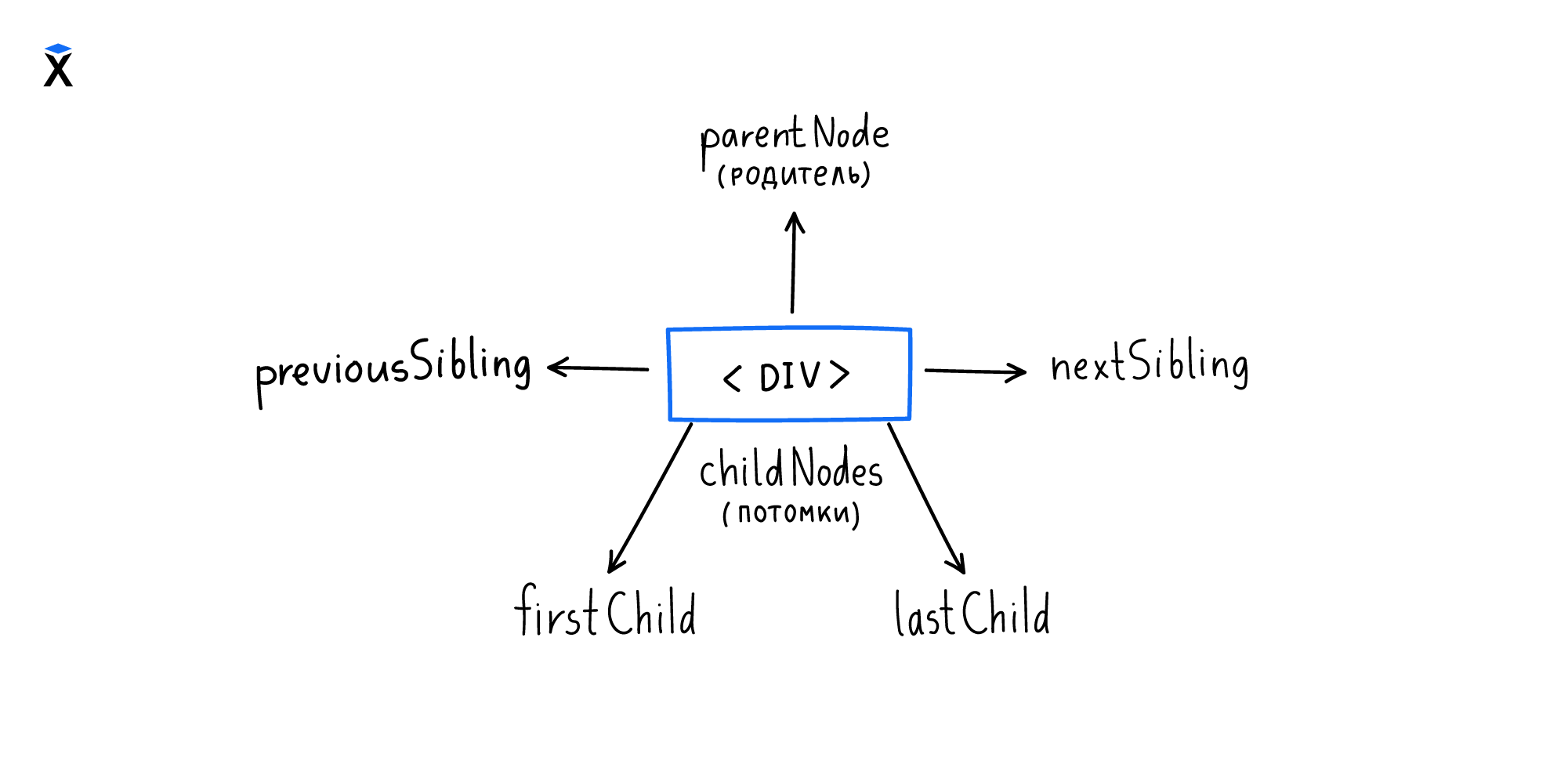
Если представить дерево, то по нему можно двигаться как вверх-вниз, так и влево-вправо. Картинка ниже это демонстрирует:
childNodes
Далее мы рассмотрим childNodes – свойство, с помощью которого можно получить дочерние узлы — это узлы, вложенные в текущий узел на один уровень вложенности. Еще говорят, что это потомки первого уровня.
В работе с childNodes есть несколько интересных моментов:
-
Это свойство доступно только для чтения. Попытка что-то записать в конкретный элемент не приведет к успеху:
Изменить DOM-дерево можно с помощью специальных методов, которые мы изучим в соответствующем уроке.
-
Хотя
childNodesи возвращает набор элементов, это все же не массив. В нем отсутствуют привычные методыmap(),filter()и другие. Но зато естьforEach():Если очень хочется, то его можно преобразовать в массив, и затем уже работать привычным способом:
Иерархия
Узлы DOM-дерева не просто так делятся на типы. Эти типы выстраиваются в иерархию от общего к частному. В иерархии подтипы наследуют свойства и методы родительских типов и добавляют свои:
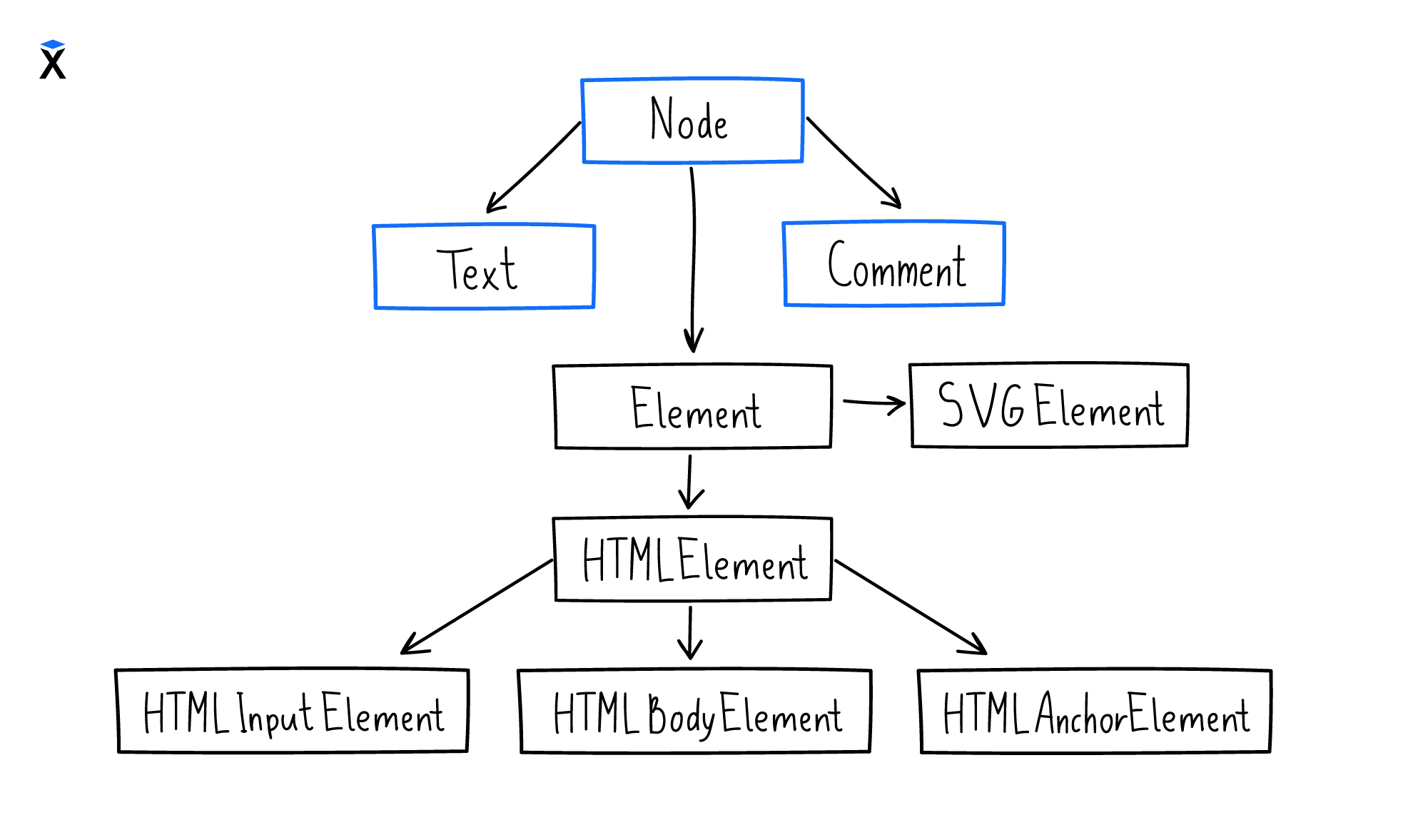
Узлы с типами Text и Comment являются листовыми, то есть они не могут иметь потомков. А вот элементы или производные типы от Element — это то, с чем приходится иметь дело чаще всего. К элементам относятся все типы, представленные тегами в HTML.
При работе с деревом естественным образом возникает понятие потомки. Применительно к DOM-дереву это означает, что тег с содержимым имеет потомков.
Посмотрите на пример кода:
В этом примере тег <div> (с id parent-div) содержит 14 потомков, в том числе три дочерних узла. Разберемся, в чем разница между этими понятиями.
Дочерними называют только те узлы, которые находятся на первом уровне вложенности. То есть дочерними будут считаться:
<h1>- Текст
"Привет!" <div>с классомchild-div
Потомками называют все вложенные узлы на всех уровнях вложенности. Потомками тега <div> (с id parent-div) будут не только три вышеупомянутых дочерних тега, но и все узлы внутри них:
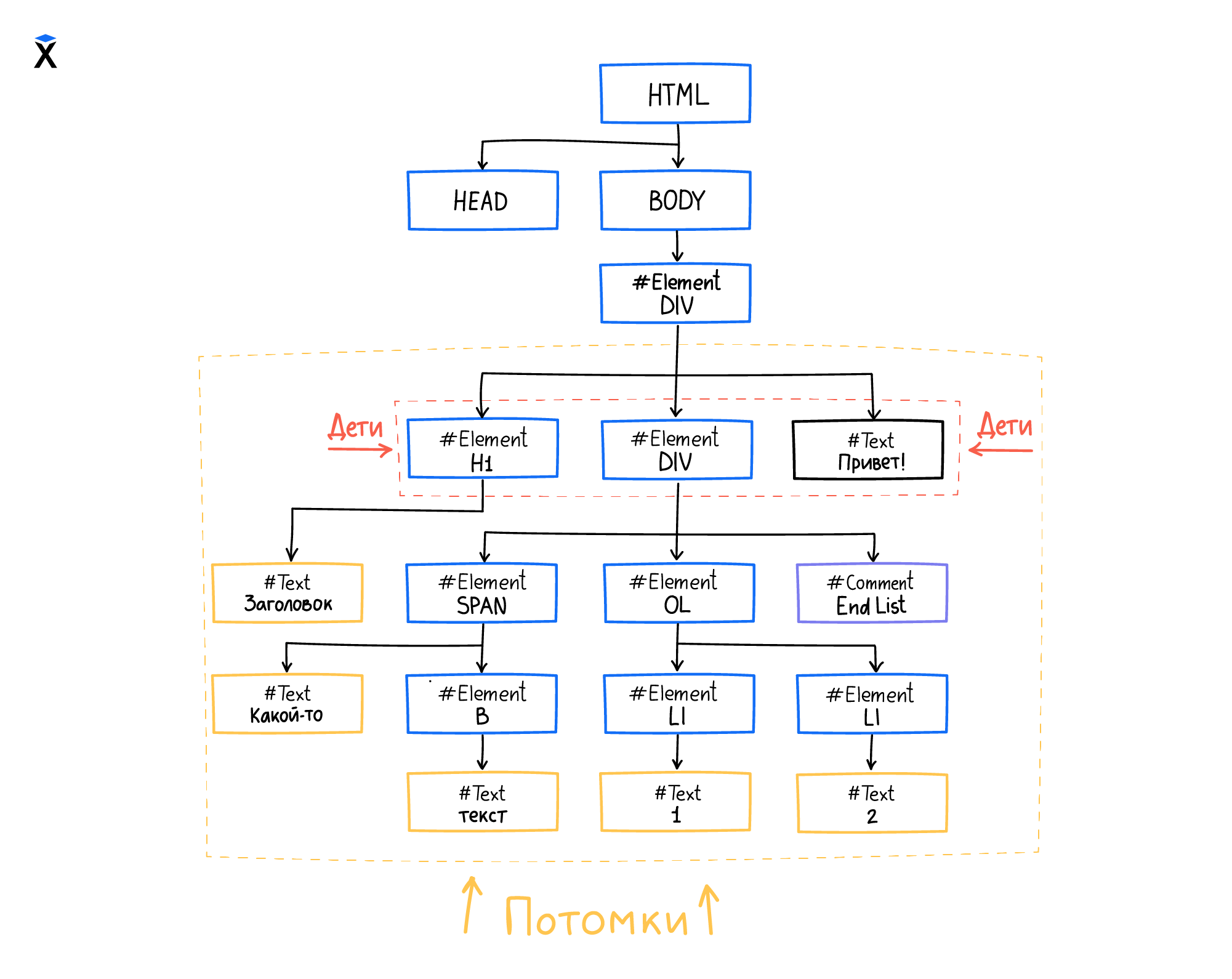
Дочерние узлы одновременно являются потомками. Обратное утверждение неверно — потомок необязательно является дочерним элементом. В нашем примере тег <span> приходится потомком, но не дочерним элементом по отношению к тегу <div> с id parent-div.
Элементы
На практике чаще всего нас интересуют не любые узлы, а элементы. Именно ими мы манипулируем, перемещаемся сквозь них. Это настолько важно, что в DOM есть альтернативный способ обхода дерева, который построен только на элементах:
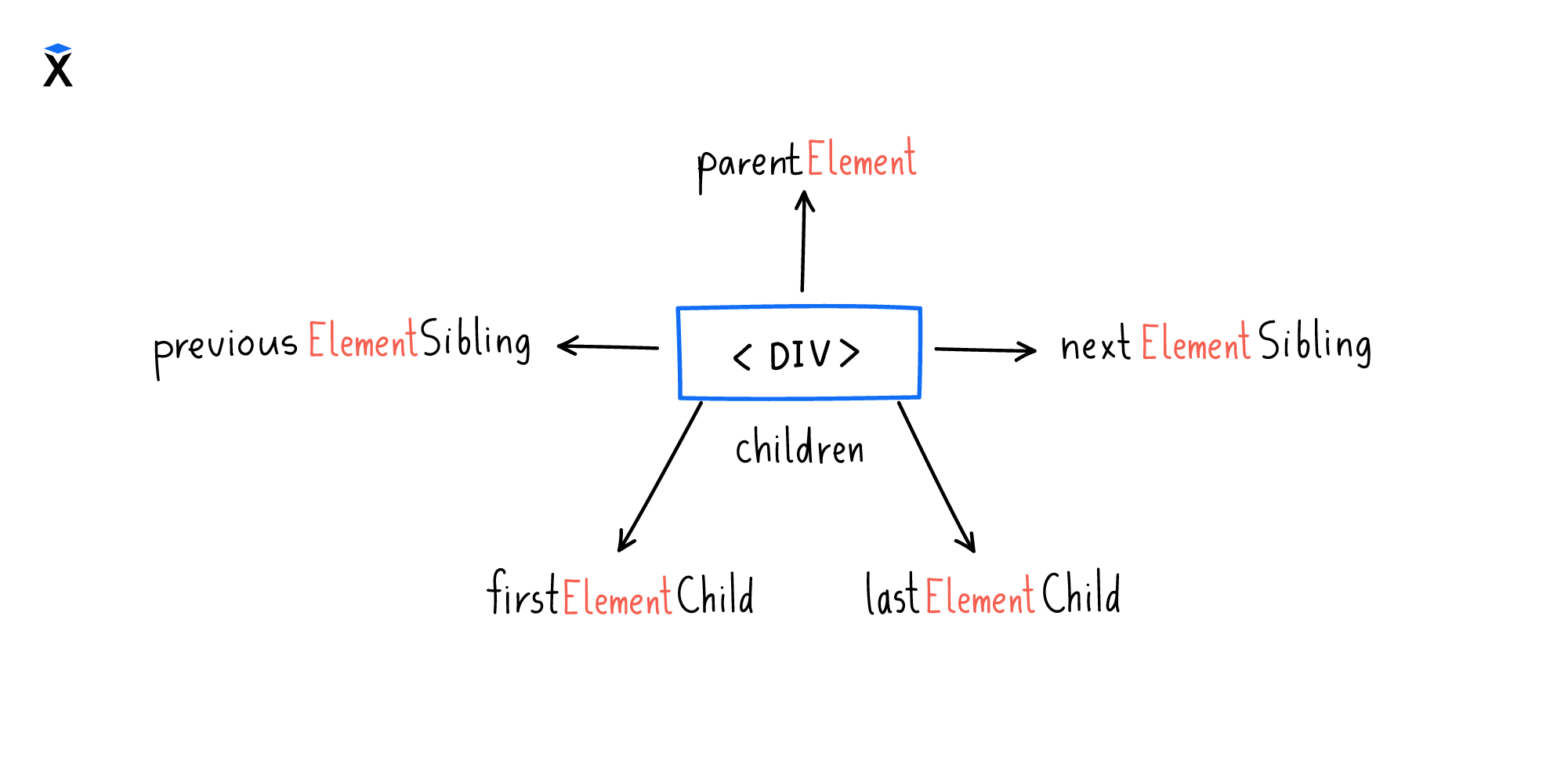
Все эти свойства возвращают объекты типа Element и пропускают объекты Text или Comment. Это видно в примере ниже, где свойство children возвращает только теги.
Этим children отличается от childNodes, который возвращает все узлы, включая листовые:
Между children и childNodes есть еще одно довольно важное отличие. Они возвращают не только разный набор узлов, но и сам тип коллекции в первом и втором случае разный:
childNodesвозвращает NodeListchildren— HTMLCollection
Они немного по-разному работают, но рассматривать эту разницу мы будем позже, когда познакомимся с селекторами.
Специальная навигация
Некоторые элементы обладают специальными свойствами для навигации по ним, к таким элементам относятся, например, формы и таблицы:
В примере выше table имеет специальные свойства для навигации rows и cells.
Этот способ навигации не заменяет основные способы. Он сделан исключительно для удобства в тех местах, где это имеет смысл. Например, таблица имеет ячейки в строках. Поэтому гораздо удобнее обращаться к строкам(англ. rows) и ячейкам(англ. cells) через индексы.
Заключение
Нужно ли все эти методы знать наизусть? В реальности — нет. Важно понимать общие принципы устройства DOM-дерева, знать иерархию типов и то, как принципиально происходит обход элементов. Конкретные методы и свойства всегда можно прочитать в документации. Наизусть их мало кто помнит, и в этом нет практического смысла.
Кроме того, обход дерева данными способами – это низкоуровневый способ работы. На практике для выборки нужных элементов используют селекторы, которые изучаются далее.



