'%3e%3cpath%20d='M13.1407%204.34375L9.12548%205.80383L6.93536%209.45402L4.38023%205.80383L0.365019%204.34375L5.11027%2011.6441L0%2019.6745H2.92015L6.57034%2013.8342L10.5856%2019.6745H13.5057L8.39544%2011.6441L13.1407%204.34375ZM17.1559%2012.0091C17.5209%2010.5491%2018.981%209.089%2020.8061%209.089C22.6312%209.089%2024.0913%2010.5491%2024.4563%2012.0091H17.1559ZM20.8061%206.89888C17.1559%206.89888%2014.2357%209.81904%2014.2357%2013.4692C14.2357%2017.4844%2017.1559%2020.0396%2020.8061%2020.0396C23.3612%2020.0396%2025.9164%2018.5795%2027.0114%2016.0244H24.0913C23.7262%2017.1194%2022.2662%2017.8495%2020.8061%2017.8495C18.616%2017.8495%2017.1559%2016.3894%2016.7909%2014.1993H27.0114C27.3764%2010.1841%2024.8213%206.89888%2020.8061%206.89888ZM40.8821%207.2639H37.597L32.1217%2012.7392V7.2639H29.5665V19.6745H32.1217V13.8342L38.327%2019.6745H41.6122L35.0418%2013.1042L40.8821%207.2639ZM48.5475%209.45402C50.0076%209.45402%2051.4677%2010.1841%2051.8327%2011.6441H54.3878C54.0228%208.72398%2051.4677%206.89888%2048.5475%206.89888C44.5323%206.89888%2041.9772%209.81904%2041.9772%2013.4692C41.9772%2017.1194%2044.5323%2020.0396%2048.1825%2020.0396C51.1027%2020.0396%2054.0228%2018.2145%2054.3878%2015.2943H51.8327C51.4677%2016.7544%2050.0076%2017.4844%2048.1825%2017.4844C45.9924%2017.4844%2044.5323%2016.0244%2044.5323%2013.4692C44.5323%2011.2791%2045.9924%209.45402%2048.5475%209.45402ZM58.403%2014.5643C58.038%2017.1194%2057.673%2017.4844%2056.2129%2017.4844H55.4829V20.0396H56.943C58.7681%2020.0396%2060.2281%2018.5795%2060.9582%2014.9293L61.6882%209.81904H66.0684V19.6745H68.6236V7.2639H59.4981L58.403%2014.5643ZM73.7338%2012.0091C74.4639%2010.5491%2075.5589%209.089%2077.7491%209.089C79.5742%209.089%2080.6692%2010.5491%2081.0342%2012.0091H73.7338ZM77.7491%206.89888C73.7338%206.89888%2071.1787%209.81904%2071.1787%2013.4692C71.1787%2017.4844%2073.7338%2020.0396%2077.7491%2020.0396C80.3042%2020.0396%2082.8593%2018.5795%2083.5894%2016.0244H81.0342C80.3042%2017.1194%2079.2091%2017.8495%2077.7491%2017.8495C75.5589%2017.8495%2074.0989%2016.3894%2073.7338%2014.1993H83.9544C84.3194%2010.1841%2081.7643%206.89888%2077.7491%206.89888ZM91.9848%207.2639H85.4145V9.81904H89.4297V19.6745H91.9848V9.81904H96V7.2639H91.9848Z'%20fill='%231D1D1B'%20/%3e%3cpath%20d='M13.1429%202.51607L6.93753%20-0.0390625L0.367188%202.51607L6.93753%204.70618L13.1429%202.51607Z'%20fill='%23136EF6'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_139_18360'%3e%3crect%20width='96'%20height='24'%20fill='%23fff'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Основы алгоритмов и структур данных
Теория: Двусвязный список
Вы уже знакомы с односвязным списком. Эта структура данных позволяет быстро вставлять и удалять элементы. Звучит удобно, но такой подход работает не во всех случаях. В этом уроке вы познакомитесь с двусвязным списком, который лучше подходит для некоторых типичных задач в программировании.
Есть несколько задач, для которых односвязный список подходит не очень хорошо. В частности, он несимметричен — если вставка и удаление в начале списка выполняются за константное время O(1), то в конце — за линейное O(n). Если в списке будет тысяча элементов, вставка в начало может оказаться в тысячу раз быстрее, чем вставка в конец.
Другая задача, которую трудно решить с помощью односвязного списка — вставка перед заданным узлом. Предположим, у нас есть текст на русском языке, где каждый элемент — либо отдельное слово, либо знак препинания. В тексте могут быть ошибки: например, могут отсутствовать запятые и точки. Мы предполагаем, что если слово начинается с большой буквы, перед ним должна быть точка. Если в тексте есть союзы «но» и «а», перед ними должна стоять запятая.
Расссмотрим такой пример:
В этом тексте не хватает запятой перед словом «но» и точки перед словом «Какое». Попробуем решить эту задачу с помощью односвязного списка. Нам нужно:
- Поместить слова в односвязный список
- Найти слово «но»
- Попробовать вставить перед ним запятую
Здесь мы сталкиваемся с тем, что в узле нет ссылки на предыдущий элемент, только на следующий:
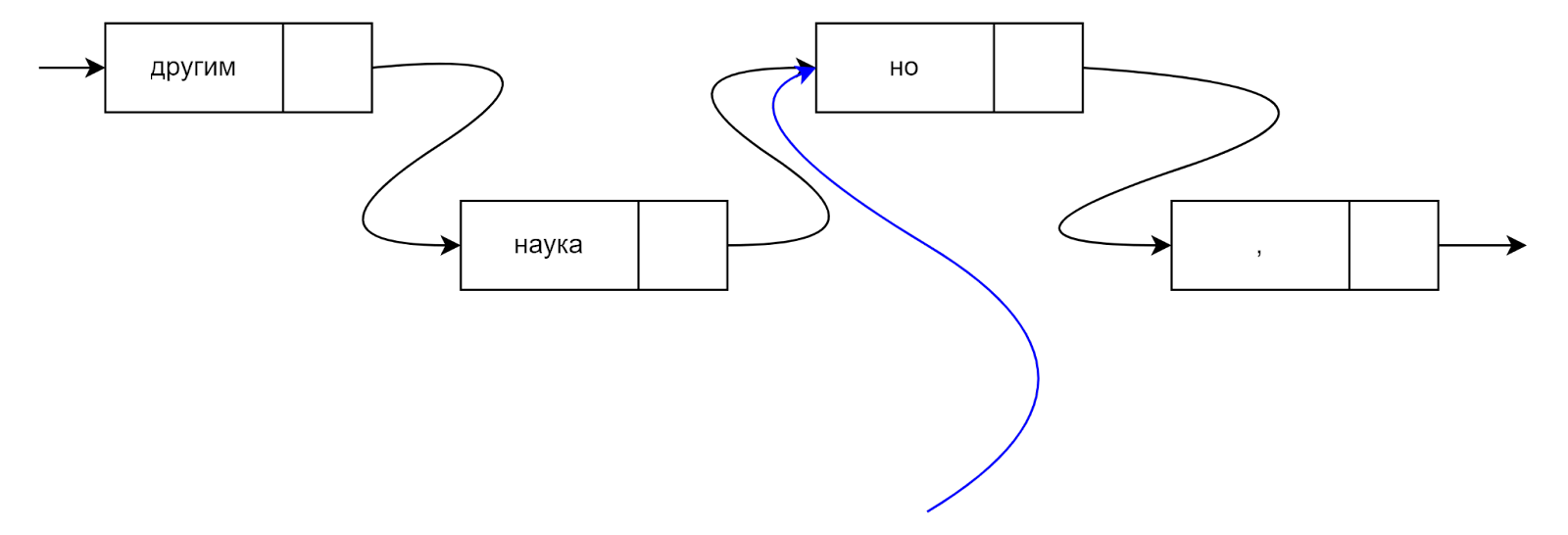
Односвязный список устроен так, что для вставки запятой между словами «наука» и «но» нужно модифицировать именно узел со словом «наука». Эти детали делают наш возможный алгоритм сложным и медленным.
Для подобных задач лучше использовать списки, в котором хранятся обе ссылки.
Двусвязный список
В каждом узле двусвязного списка хранится две ссылки — на следующий и на предыдущий узел. Кроме того, в нем хранятся ссылки и на голову списка (первый элемент), и на его хвост (последний элемент):
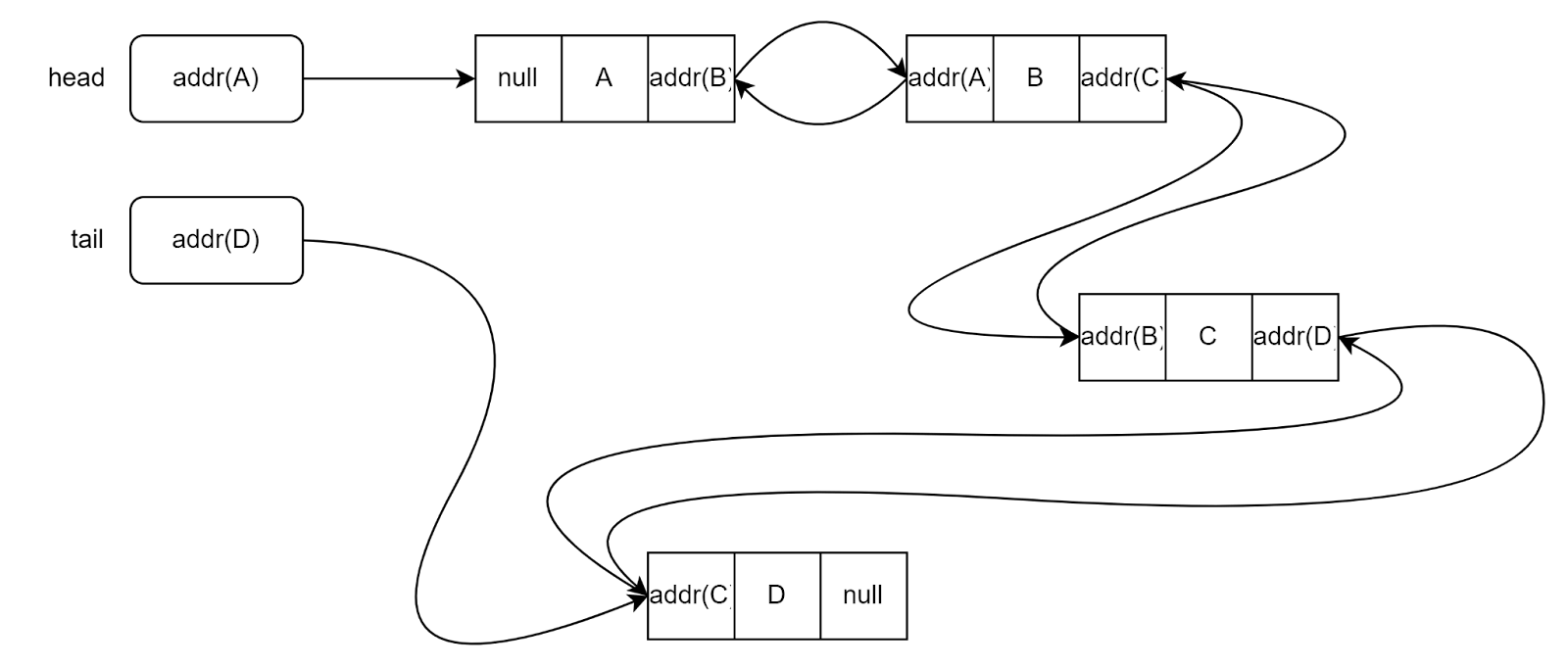
Как и в случае с односвязным списком, нам приходится особым образом хранить ссылку на следующий узел для последнего узла. Там мы помещаем значение null — пустую ссылку, которая ни на что не указывает. На рисунке последний узел в списке — это D.
У первого узла не может быть предыдущего узла, поэтому и здесь мы записываем null вместо ссылки. На рисунке первый узел в списке — это A.
За счет изменения структуры, мы получаем две новые возможности:
- Вставка и удаление в конце списка становятся настолько же быстрыми, как и в начале. Теперь они выполняются за константное время O(1)
- Вставка узла перед заданным узлом становится такой же простой операцией, как и вставка после
Конечно, есть и минусы. Во-первых, сама структура и код становятся сложнее. Во-вторых, структура теперь занимает больше памяти, поскольку в каждом узле хранится две ссылки, а не одна.
Вставка узла в начало списка
Посмотрим, как выглядит вставка узла в начало списка:
Разберем этот фрагмент кода подробнее.
Двусвязный список, как и односвязный, требует определения двух классов:
Первый класс — DoublyLinkedListNode. Он описывает узел двусвязного списка и состоит из таких компонентов:
- Значения —
value - Ссылки на предыдущий узел —
previous - Ссылки на следующий узел —
next
Второй класс — DoublyLinkedList. Он представляет список целиком, вместе с его операциями-алгоритмами. Там находятся:
- Ссылка на первый узел —
head - Ссылка на последний узел —
tail - Различные методы, например:
insertBegin(value)— вставка в началоinsertEnd(value)— вставка в конецremoveBegin()— удаление из начала
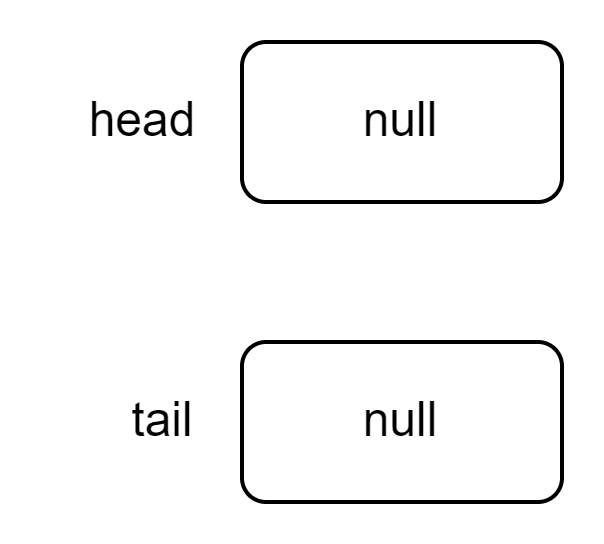
Новый список пуст, поэтому поля head и tail содержат значение null:
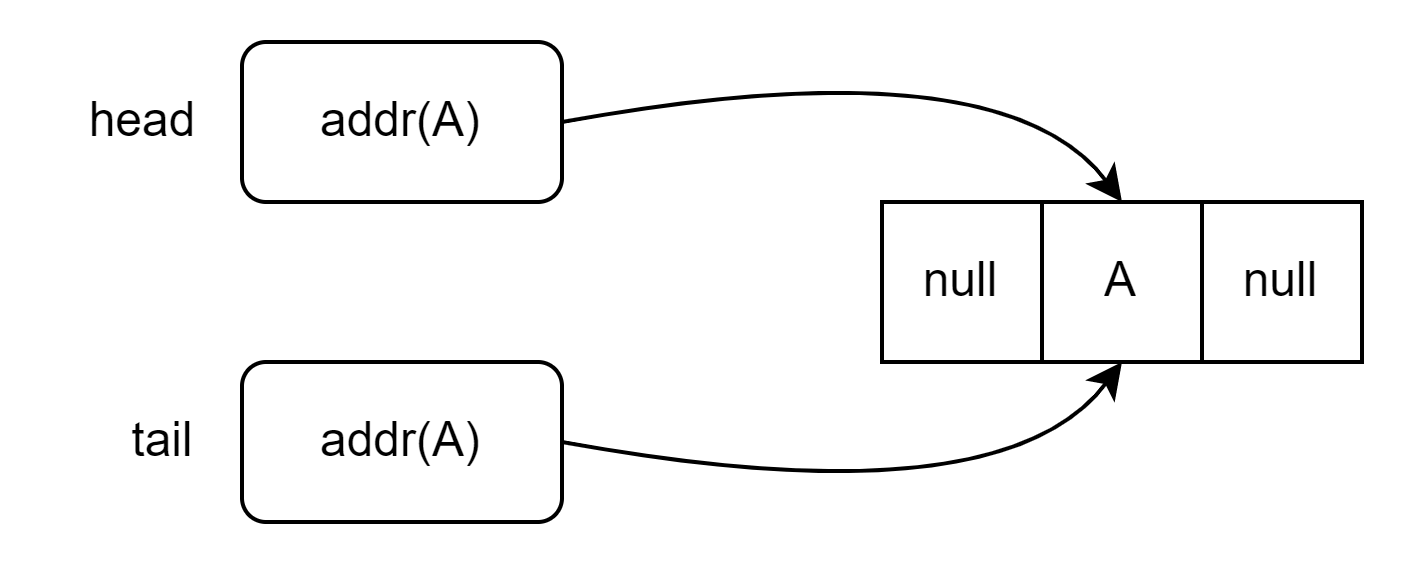
После вставки первого узла head и tail содержат его адрес. При этом поля previous и next у этого узла никуда не указывают, потому что он одновременно является первым и последним в списке — другими словами, у него нет ни предыдущего, ни следующего узла:
Теперь посмотрим на фрагмент кода:
Условие this.head == null выполняется для пустого списка. Нам достаточно создать узел с пустыми ссылками на предыдущий и следующий узлы, а затем присвоить его адрес полям this.head и this.tail.
При вставке каждого следующего узла в начало, head всегда будет указывать на новый узел. Значение tail при этом не изменится, потому что хвост списка остается прежним. Поле next новой головы списка будет указывать на прежнюю голову, а в поле previous старой головы вместо null должен появиться адрес новой головы:
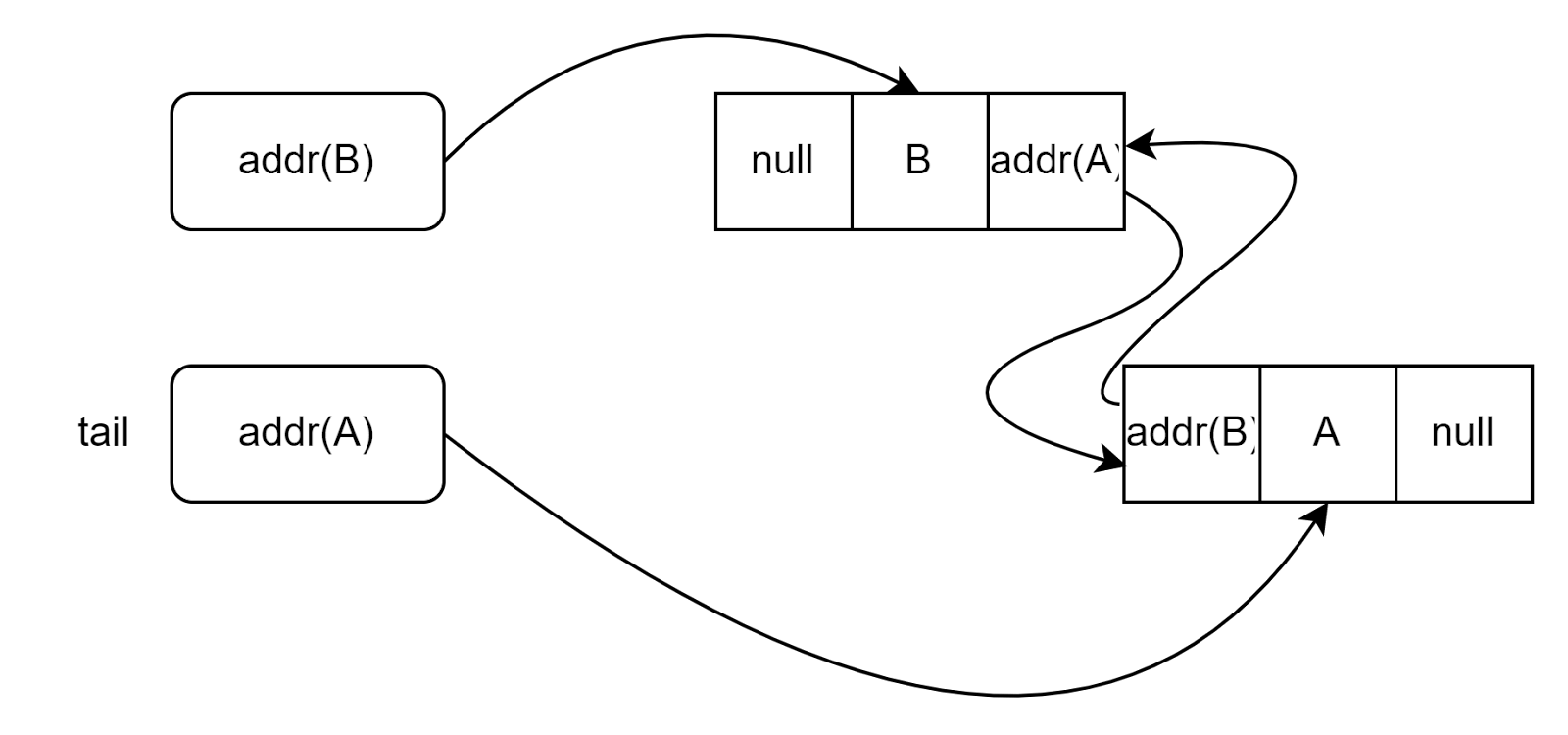
Это довольно сложная логика, которая требует аккуратной реализации и проверки граничных условий. Поэтому код методов двусвязного списка сложнее, чем код методов односвязного. Посмотрите на этот пример:
Создавая узел, мы сразу записываем в поле next текущее значение this.head— текущую голову. Поле previous текущей головы должно ссылать на новый узел, за это отвечает такая строка:
Наконец, новый узел становится новой головой списка:
Вставка узла в конец списка
Перейдем к вставке узла в конец списка:
Такая вставка симметрична вставке в начало. Разница только в том, что здесь мы должны везде менять местами head и tail, а также previous и next.
Удаление узла
Перейдем к операциям удаления:
Метод удаления возвращает значение из удаленного узла. Если список пуст и удалять нечего, метод возвращает undefined. В остальных случаях мы сохраняем значение в переменную result:
Если this.head == this.tail, значит, в списке находится один последний узел — он является одновременно и головой, и хвостом. Чтобы его удалить, достаточно обнулить head и tail:
А теперь посмотрим обратный пример — избавимся от первого узла в списке. Сначала записываем в head ссылку на второй узел, а потом обнуляем у нее поле previous:
Перебор значений в прямом порядке
Раньше для работы с массивами, связными и двусвязными списками, программисты писали разный код. Например, если надо было просуммировать элементы массива и элементы связного списка, приходилось писать две похожие функции. Каждая из них складывала элементы коллекций, но доступ к этим элементам у массива и списка был разным.
Дублирование кода — одна из самых неприятных вещей в программировании. При внесении правок можно забыть поменять код в одной из копий и это приведет к ошибкам, которые трудно обнаружить. Но есть решение этой проблемы: в языках постоянно появляются новые инструменты, которые помогают избавиться от старых ошибок и реже дублировать код.
Чтобы просуммировать элементы из разных структур данных, сейчас достаточно написать всего одну функцию. Это стало возможным благодаря итераторам. Обычно итерацией в программировании называют отдельный шаг цикла. Но у слова есть и другое значение.
Итератор — это объект, который одинаковым образом перебирает элементы коллекции, независимо от структуры данных. Скажем, мы можем написать функцию суммирования элементов любой коллекции и вызвать ее для списка:
Эта функция сможет работать и с нашим двусвязным списком, но для этого нам потребуется реализовать собственный итератор.
Однако, здесь есть проблема. Массив и односвязный список имеют естественный порядок перебора — от начала к концу. В двусвязном списке поддерживаются два равноправных порядка:
- От начала к концу
- От конца к началу
Поэтому двусвязный список должен иметь два итератора — прямой и обратный. Чтобы так сделать, можно возвращать итераторы из методов класса. Например, метод fore() может создавать и возвращать прямой итератор:
Использовать итератор можно так:
В JavaScript используется синтаксис function* и yield, который упрощает работу с итераторами. В нашем примере порядок действий такой:
- Начинаем с первого узла, адрес которого хранится в поле head
- Пробегаем по всем узлам списка
- Передаем значения узлов в вызывающую функцию с помощью конструкции
yield
Выводы
- Односвязный список подходит не для всех задач — он предоставляет только последовательный доступ к последующим элементам
- Чтобы справиться с этими трудностями, программисты используют такую структуру данных, как двусвязный список.
- В каждом узле двусвязного списка хранится не только ссылка на следующий узел (как у односвязного), но и на предыдущий.
- К плюсам двусвязного списка можно отнести возможность «пробегать» по списку как вперед, так и назад, а к минусам — сложный код и больший расход памяти.
- Итераторы позволяют писать один код для работы с коллекциями разных типов. Мы можем реализовать итераторы для тех структур данных, которые мы разрабатываем.
