Продвинутая аналитика на SQL
Теория: Концепция витрины
В этом уроке мы познакомимся с понятиями баз и витрин данных компании и их различиями. Витрины — важная тема для аналитика данных, так как он работает именно с ними.
Сегодня мы научимся создавать витрины и работать с ними. Эти навыки помогут построить аналитические отчеты и выявить причины проблем в работе сервисов компании. Например, построить отчет о выручке магазинов сети за период времени и найти самые прибыльные магазины.
Базы данных систем
Представим, что мы ведем заметки о своей жизни и работе в разных местах. Для учета доходов и расходов мы используем Google-таблицы или специальные приложения. Трекинг рабочих задач производим в Trello. А в Notion записываем мысли о событиях из жизни и ведем дневник. Каждый из этих инструментов удобен для определенных задач.
Это примеры баз данных, которые мы используем в личных целях. У компаний тоже есть разные базы для разных подсистем. Например, у бухгалтерии банка своя база данных, у отдела продаж своя, у отдела кредитного скоринга тоже своя.
Обычно базы данных подсистем компании хранятся в нормализованном виде. Покажем, как это выглядит на примере.
Допустим, мы отслеживаем ежемесячный поток клиентов в нескольких магазинах сети электроники. Клиенты пользуются именными скидочными картами, и по ним мы отслеживаем каждого по отдельности. Тогда таблица с данными клиентов и купленных ими товарами будет выглядеть так:
Purchases
В этой таблице мы видим информацию о транзакциях покупателей в магазине электроники. Здесь есть информация о покупателях, магазинах и товарах.
Теперь представим, что один из магазинов переехал на другой адрес. Чтобы внести изменения в эту таблицу, мы выделим все строки, которые содержат старый адрес, и заменим на новый.
Если в таблице тысячи или миллионы строк, тогда придется изменять большое количество. Но это замедляет работу сервиса, и даже может положить его.
Чтобы не столкнуться с этой проблемой, базы данных таких систем нормализуют — разносят разные объекты по разным таблицам. В таком случае предстоит изменять минимальное количество строк.
Так выглядят нормализованные таблицы:
Shops
Customers
Products
Discounts
CustomersDiscounts
Purchases
Датасет доступен на DB Fiddle по этой ссылке.
Здесь представлены следующие таблицы:
- Shops — информация о магазинах
- Customers — информация о клиентах
- Products — информация о товарах
- Discounts — информация о скидках
- CustomersDiscounts — таблица, которая связывает клиентов и их персональные скидки
- Purchases — таблица покупок
У каждой из этих таблиц есть поле ID — это уникальный ключ. Также одна таблица содержит в себе информацию только об одной сущности, например: Shops — о магазинах, Customers — о клиентах.
Каждый объект, например, магазин, клиент, представлены одной строкой без дублирования. При этом таблица Purchases может содержать одинаковые ID клиентов, товаров или магазинов, так как клиенты покупают товары в разных магазинах в разное время или одни и те же товары.
Если заменить адрес магазина, мы затронем одну строчку в таблице с магазинами. Остальные таблицы останутся без изменений.
CustomersDiscounts — это отдельный вид таблиц. Они содержат в себе только свой ID и ID других таблиц, что позволяет связать эти таблицы. Покупателей и их индивидуальные скидки разносят по разным таблицам.
Например, скидка у отдельного покупателя может увеличиться, когда он за все время купил в магазине много товаров. Мы хотим изменять как можно меньшее количество строк, поэтому меняем значение скидки в CustomersDiscounts, а таблица Customers остается без изменений.
Такие базы данных называются OLTP или Online Transaction Processing. Online — потому, что базы данных обновляются в реальном времени. Транзакции идут большим потоком, поэтому, чтобы достичь минимального времени отклика, важно вносить изменения в малое количество строк.
Витрины данных
Аналитикам данных сложно работать с большим количеством таблиц, так как каждая из них неинформативная. Аналитики интересуются не ID товаров или магазинов, им нужно знать названия товаров, адреса магазинов, цены с учетом скидки и так далее. Поэтому существуют витрины данных, где собрана вся важная информация.
Пример витрины данных — это таблица Purchases. Посмотрим на нее еще раз:
Purchases
Здесь находится только важная информация: имена клиентов, наименование купленного товара, адрес покупки, и нет ID. Аналитики работают только с витринами, потому что они удобны для анализа и построения отчетов.
Напомним, что обычно в компаниях базы данных для каждого отдела разные. Аналитики обычно не анализируют все данные сразу, поэтому витрины — это срез во всех данных компании. Их еще называют Data Mart.
Представим общую схему потока данных между базами разных отделов и витринами:
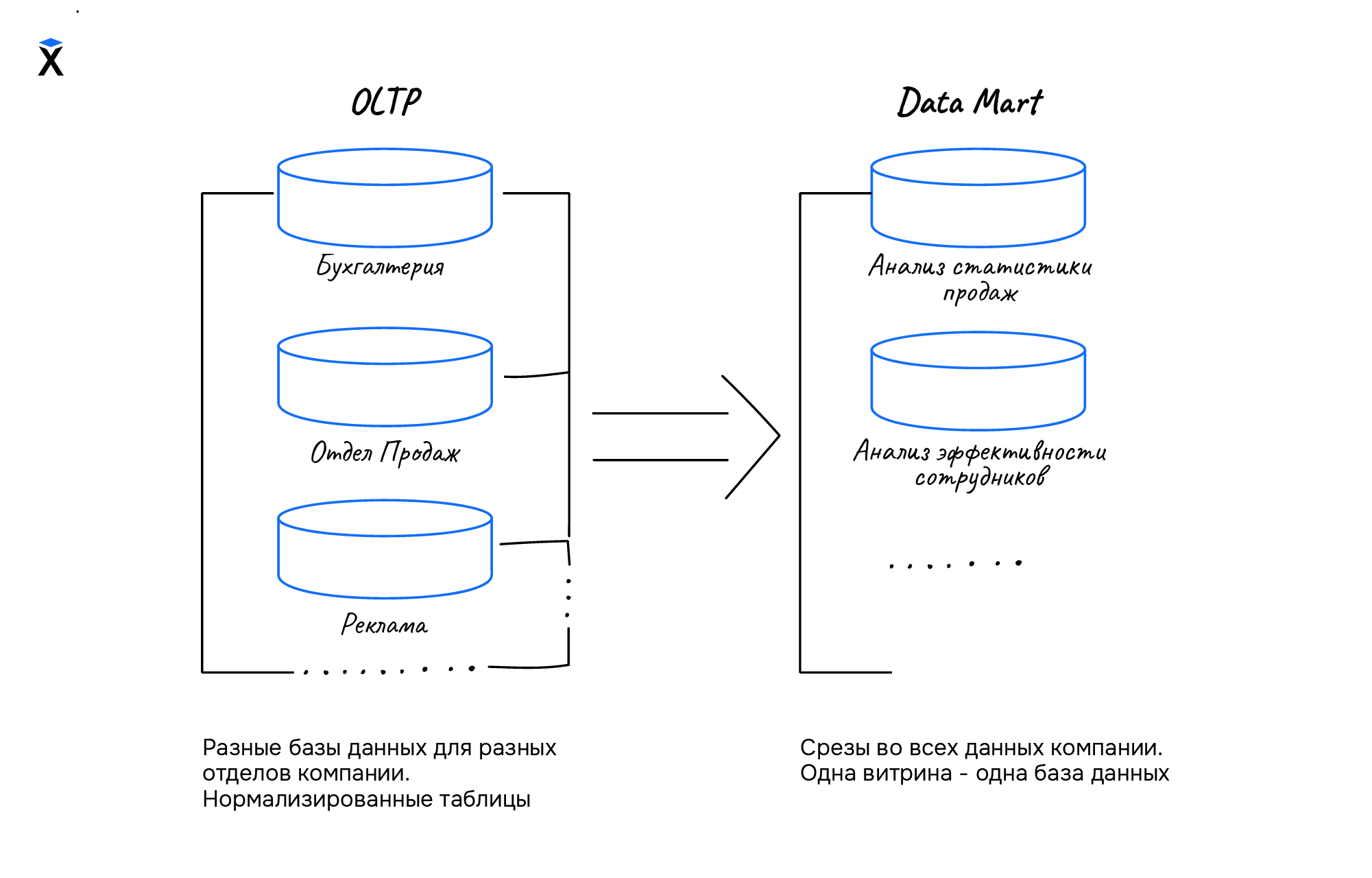
Здесь видно, что каждый отдел компании содержит свою базу данных, а таблицы в базах хранятся в нормализованном виде. Витрины данных — это срезы в хранилище данных для разных аналитических задач. Одна витрина представляется не более чем одной базой.
Витрины данных могут быть базами данных или таблицами в Google Sheets, это не меняет их сути.
Теперь разберемся, как работать с витриной. Для этого создадим ее.
Создаем витрину
Откроем базу данных Purchases. Мы увидим в ней таблицы, которые были в примерах урока:
- Customers
- CustomersDiscounts
- Discounts
- Products
- Purchases
- Shops
Посмотрим на таблицу Purchases:
purchases.purchases
В этой таблице 13 строк, каждая строка — отдельная покупка. Нам нужно получить таблицу, где вся информация представлена понятным
образом, а не через id. Выпишем все поля, которые хотим получить в витрине:
date— дата покупкиfull_name— ФИО покупателяshop_address— адрес магазинаproduct_name— наименование товараprice— исходная цена товара в рубляхdiscount— скидка в долях от единицыdiscounted_price— цена товара после индивидуальной скидки покупателю
Таблица Purchases будет основной связующей с другими таблицами. Друг с другом связаны только таблицы customers и discounts через
промежуточную таблицу customersdiscounts.
Чтобы создать витрину, нужно объединить нормализованные таблицы джойнами. В нашем случае в таблицах нет NULL-значений, поэтому мы можем использовать любой вид джойнов, например, INNER JOIN. INNER JOIN — это разновидность джойна, которая связывает таблицы по ненулевым ключам. Если ключ какой-то строки имеет значение NULL, эта строка не попадает в итоговую таблицу.
Если в ключах есть NULL-значения, а мы все равно хотим включить эти строки в итоговую таблицу, мы воспользуемся LEFT JOIN, RIGHT JOIN или FULL OUTER JOIN. В таком случае мы выберем джойн исходя из того, включать ли нулевые ключи только левой таблицы, правой или обеих.
Теперь нужно понять, откуда взять нужные нам поля. Например, date — это дата покупки, поэтому возьмем ее из таблицы Purchases. А full_name есть в таблице customers. Попробуем составить селект, чтобы получить два этих поля:
В customers id покупателя называется id, так как эта таблица про покупателей, и id покупателя в ней — это уникальный ключ. А таблица Purchases о покупках. Покупатели в ней могут повторяться, поэтому поле называется customer_id.
shop_address — это адрес магазина, то есть поле address в таблице Shops. Добавим джойн с этой таблицей:
product_name и price мы возьмем из таблицы Products:
Остались поля discount и discounted_price. Мы помним, что таблицы Discount и Customers связаны через CustomersDiscounts. Поэтому мы объединим скидки с покупателями через дополнительную таблицу. В итоге посчитаем discounted_price по следующей формуле:
Итоговый запрос будет выглядеть так:
data_mart
Работаем с витриной
Допустим, нам нужно посчитать суммарную выручку по каждому из магазинов. Для этого используем агрегирующую функцию SUM с группировкой по магазинам. Функция SUM позволяет посчитать сумму всех значений покупок в каждой из групп. Группы формируются с помощью GROUP BY, и наши группы — это каждый отдельный магазин.
Для начала создадим новую таблицу purchasesDataMart и запишем в нее нашу витрину. Мы создаем новую таблицу, чтобы в дальнейшем можно было обращаться только к ней с другими запросами.
В запросе выше мы объединили все таблицы в одну и записали нашу витрину в новую таблицу.
Теперь мы можем составить запрос к таблице витрины:
Итоговая таблица выглядит так:
purchases.purchasesDataMart
В этой таблице мы видим суммарную выручку по каждому из магазинов в колонке total_earnings.
Мы создали витрину данных и записали ее в таблицу purchasesDataMart, а также создали свой первый отчет по витрине.
Выводы
В этом уроке мы рассмотрели концепцию OLTP и витрин данных. Витрины данных — это срезы во всех данных компании, которые интересны аналитику данных. Витрины содержат в себе более информативные таблицы, чем базы OLTP, которые нормализованы и связаны друг с другом с помощью ключей id.
Мы научились создавать витрину. Чтобы превратить таблицы в базе в витрину, нужно объединить информативные поля из разных таблиц по ключам. Главный ключ в каждой из таблиц — это уникальное поле. Обычно он называется id.
Когда у нас уже есть витрина, мы можем строить по ней отчеты и выявлять закономерности.
Витрины данных очень важны в аналитике данных, и вы будете с ними постоянно сталкиваться в дальнейшем.

