'%3e%3cpath%20d='M13.1407%204.34375L9.12548%205.80383L6.93536%209.45402L4.38023%205.80383L0.365019%204.34375L5.11027%2011.6441L0%2019.6745H2.92015L6.57034%2013.8342L10.5856%2019.6745H13.5057L8.39544%2011.6441L13.1407%204.34375ZM17.1559%2012.0091C17.5209%2010.5491%2018.981%209.089%2020.8061%209.089C22.6312%209.089%2024.0913%2010.5491%2024.4563%2012.0091H17.1559ZM20.8061%206.89888C17.1559%206.89888%2014.2357%209.81904%2014.2357%2013.4692C14.2357%2017.4844%2017.1559%2020.0396%2020.8061%2020.0396C23.3612%2020.0396%2025.9164%2018.5795%2027.0114%2016.0244H24.0913C23.7262%2017.1194%2022.2662%2017.8495%2020.8061%2017.8495C18.616%2017.8495%2017.1559%2016.3894%2016.7909%2014.1993H27.0114C27.3764%2010.1841%2024.8213%206.89888%2020.8061%206.89888ZM40.8821%207.2639H37.597L32.1217%2012.7392V7.2639H29.5665V19.6745H32.1217V13.8342L38.327%2019.6745H41.6122L35.0418%2013.1042L40.8821%207.2639ZM48.5475%209.45402C50.0076%209.45402%2051.4677%2010.1841%2051.8327%2011.6441H54.3878C54.0228%208.72398%2051.4677%206.89888%2048.5475%206.89888C44.5323%206.89888%2041.9772%209.81904%2041.9772%2013.4692C41.9772%2017.1194%2044.5323%2020.0396%2048.1825%2020.0396C51.1027%2020.0396%2054.0228%2018.2145%2054.3878%2015.2943H51.8327C51.4677%2016.7544%2050.0076%2017.4844%2048.1825%2017.4844C45.9924%2017.4844%2044.5323%2016.0244%2044.5323%2013.4692C44.5323%2011.2791%2045.9924%209.45402%2048.5475%209.45402ZM58.403%2014.5643C58.038%2017.1194%2057.673%2017.4844%2056.2129%2017.4844H55.4829V20.0396H56.943C58.7681%2020.0396%2060.2281%2018.5795%2060.9582%2014.9293L61.6882%209.81904H66.0684V19.6745H68.6236V7.2639H59.4981L58.403%2014.5643ZM73.7338%2012.0091C74.4639%2010.5491%2075.5589%209.089%2077.7491%209.089C79.5742%209.089%2080.6692%2010.5491%2081.0342%2012.0091H73.7338ZM77.7491%206.89888C73.7338%206.89888%2071.1787%209.81904%2071.1787%2013.4692C71.1787%2017.4844%2073.7338%2020.0396%2077.7491%2020.0396C80.3042%2020.0396%2082.8593%2018.5795%2083.5894%2016.0244H81.0342C80.3042%2017.1194%2079.2091%2017.8495%2077.7491%2017.8495C75.5589%2017.8495%2074.0989%2016.3894%2073.7338%2014.1993H83.9544C84.3194%2010.1841%2081.7643%206.89888%2077.7491%206.89888ZM91.9848%207.2639H85.4145V9.81904H89.4297V19.6745H91.9848V9.81904H96V7.2639H91.9848Z'%20fill='%231D1D1B'%20/%3e%3cpath%20d='M13.1429%202.51607L6.93753%20-0.0390625L0.367188%202.51607L6.93753%204.70618L13.1429%202.51607Z'%20fill='%23136EF6'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_139_18360'%3e%3crect%20width='96'%20height='24'%20fill='%23fff'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Terraform: Основы
Теория: Источники данных
Когда мы используем подход «инфраструктура как код», мы стремимся описывать кодом все инфраструктурные решения. В идеале вся наша облачная инфраструктура должна быть описана в Terraform. Тогда мы сможем легко управлять зависимостями ресурсов друг от друга.
На практике такое возможно не всегда. Например, можно прийти к использованию Terraform, когда на проекте уже развернута работающая инфраструктура в облаке. Мигрировать ее в Terraform будет трудозатратно — потребуется описать в Terraform все компоненты с актуальными параметрами, а затем импортировать каждый компонент в состояние Terraform.
Если мы не мигрируем старую инфраструктуру, нам нужно научить взаимодействовать новую инфраструктуру, описанную в Terraform, со старой. Например, у нас в облаке уже есть кластер баз данных, и мы хотим обеспечить доступ к нему с новых серверов, которые создаем через Terraform:
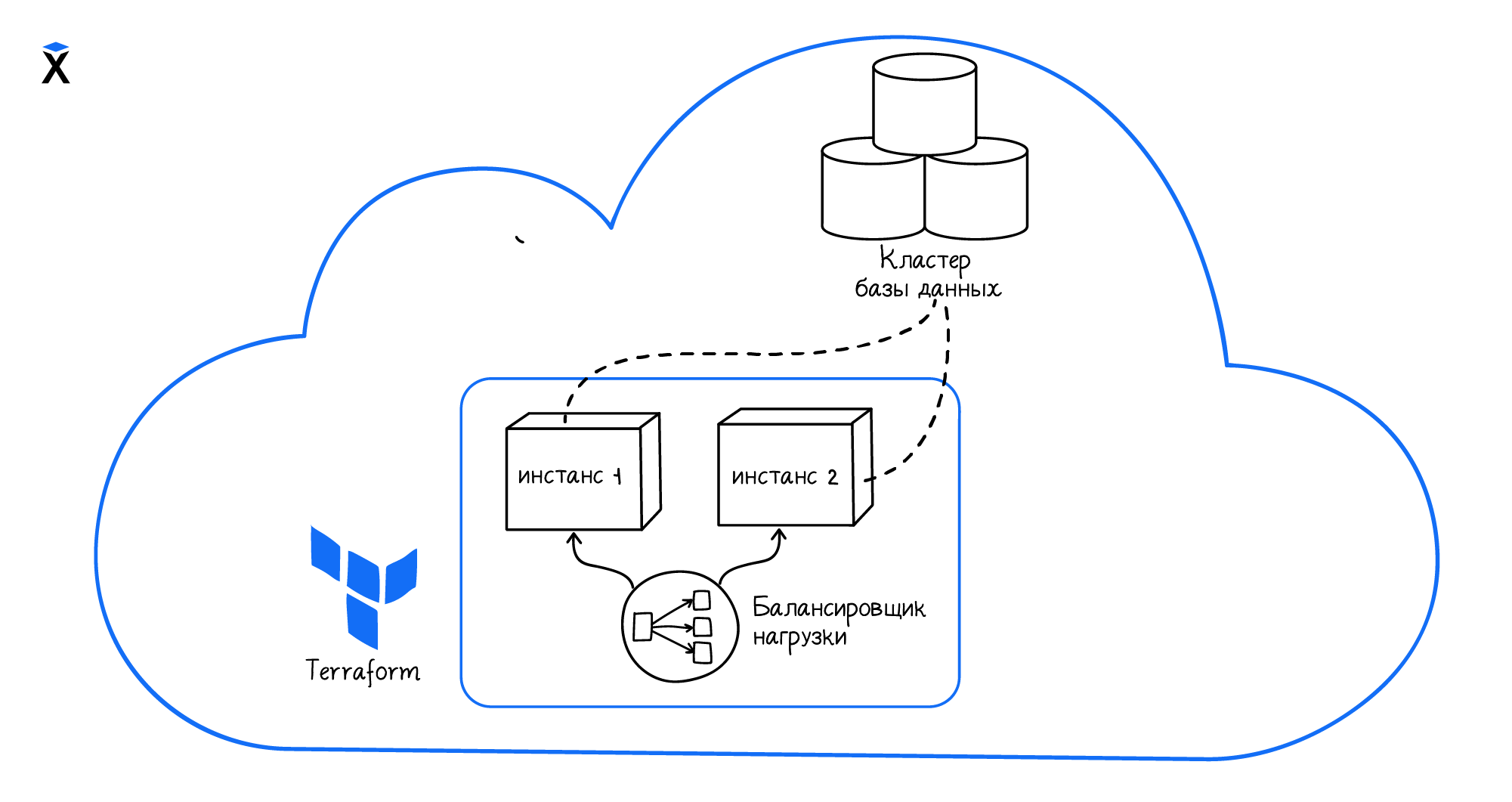
Terraform видит только те ресурсы, которые сам создал в рамках проекта. Чтобы получить информацию о кластере баз данных, созданном снаружи проекта, нам потребуется отдельный инструмент — источник данных.
В этом уроке мы познакомимся с источниками данных и выясним, какие проблемы они решают. Также мы научимся использовать их для получения информации о внешней инфраструктуре.
Что такое источник данных в Terraform
Data source в Terraform — это способ получать актуальную информацию о состоянии существующих облачных ресурсов. Мы можем описывать в проекте источники, чтобы обращаться к чему-то, что не создано и не управляется в проекте Terraform.
Например, с помощью источников мы можем получить информацию о конкретном образе виртуальной машины из каталога облака. Или узнать внешний IP виртуальной машины, чтобы создать под него DNS-запись.
Разберем, почему мы не можем все описать ресурсами Terraform:
- Есть старая облачная инфраструктура, которую мы пока не готовы мигрировать в Terraform
- Некоторыми ресурсами управляет сам провайдер. Они не могут быть описаны в вашей инфраструктуре как ресурсы
- Облако и его Terraform-провайдер развиваются несинхронно. В облаке могут реализовать новый нужный инструмент, а ресурс для него в Terraform может появиться только через месяц. Сначала мы подключаем инструмент, а его описание в коде происходит позже
- Если строить сложную инфраструктуру, можно использовать несколько проектов Terraform. Их ресурсы будут управляться независимо друг от друга, но при этом они должны взаимодействовать друг с другом
Источники данных в большинстве таких ситуаций играют роль связующих звеньев. Они позволяют инфраструктуре взаимодействовать с окружающим миром.
Далее рассмотрим простой и частый сценарий, в котором может использоваться источник данных.
Получаем id образа виртуальной машины
Начнем с источника данных, который предоставит информацию об образе Ubuntu 22.04 из библиотеки Yandex Cloud. Образы в большинстве облаков относятся к ресурсам, которыми управляет сам провайдер:
Это стандартный для Terraform формат описания источника данных. Мы обозначаем источник ключевым словом data, далее в кавычках пишем "yandex_compute_image" — тип источника из спецификации провайдера. Дальше указываем имя "img", по которому ресурсы и другие объекты смогут обращаться к источнику.
При выполнении terraform apply Terraform обратится к облаку и попытается найти образ по заданному ключу. В нашем случае он будет искать образ из семейства ubuntu-2204-lts. Если он найдет его, то сохранит найденную информацию в объект data. После этого инфраструктура Terraform сможет использовать ее.
Посмотрим, что сохранил Terraform в источник. Для этого воспользуемся блоком output:
Мы передали в value полное содержимое источника img. Чтобы обратиться к содержимому источника данных, мы используем конструкцию data.<TYPE>.<NAME>, где:
TYPE— тип источника данныхNAME— имя источника
Запустим terraform apply, не подтверждая выполнение, и посмотрим, что происходит:
data.yandex_compute_image.img: Reading...
data.yandex_compute_image.img: Read complete after 0s [id=fd8k3a6rj9okseiqrl3k]
Changes to Outputs:
+ show-img = {
+ created_at = "2023-05-29T10:50:23Z"
+ description = "ubuntu 22.04 lts"
+ family = "ubuntu-2204-lts"
+ folder_id = "standard-images"
+ id = "fd8k3a6rj9okseiqrl3k"
+ image_id = "fd8k3a6rj9okseiqrl3k"
+ name = "ubuntu-22-04-lts-v20230529"
+ os_type = "linux"
...
}
You can apply this plan to save these new output values to the Terraform state, without changing any real infrastructure.
Еще до применения изменений Terraform сходил в облако, нашел ресурс образа с заданным значением family и сохранил информацию о нем. Мы можем обращаться к полям источника в ресурсах, используя конструкцию вида data.<TYPE>.<NAME>.<FIELD>.
Например, мы можем передать виртуальной машине id образа из нашего источника img таким образом:
В данном случае мы достаем из источника data.yandex_compute_image.img значение id, которое он получил в момент запуска команды terraform apply.
Так источник данных помог привязать инфраструктуру Terraform к объекту, который существует снаружи.
Теперь разберем сценарий, описанный в начале урока. Попробуем подключить новые виртуальные машины к существующему в облаке кластеру баз данных.
Пример с базой данных
Рассмотрим практический пример с кластером баз данных. Допустим, у нас в облаке уже развернут кластер БД с именем postgresql14. Мы воспользуемся источником данных, чтобы узнать, как к нему подключаться. Далее передадим информацию об этом новому виртуальному серверу.
Опишем источник данных, который извлечет информацию о кластере:
Источник типа yandex_mdb_postgresql_cluster возвращает сложную структуру данных. С ней можно ознакомиться в документации источника либо вывести содержимое источника с помощью output, как делали выше.
Нам сейчас не нужна вся структура, а нужно конкретное поле data.yandex_mdb_postgresql_cluster.dbcluster.host.0.fqdn. Оно содержит имя хоста для подключения к кластеру.
Возьмем у кластера имя для подключения и добавим его в переменные окружения новой создаваемой в Terraform виртуальной машины:
В user-data с помощью конструкции EOF мы описали bash-скрипт, который при запуске виртуальной машины добавит строку export DB_HOST=<путь к Managed DB> в /etc/environment.
Имена переменных и логические конструкции Terraform внутри скрипта мы оборачиваем в ${...}. Так мы используем интерполяцию, чтобы Terraform до выполнения операций получил значения data.yandex_mdb_postgresql_cluster.dbcluster.host.0.fqdn и file("~/.ssh/id_rsa.pub") и сконвертировал их в строки.
В итоге после запуска в env сервера будет переменная DB_HOST, которую он сможет использовать для подключения приложения к кластеру БД:

При этом источник данных будет всегда предоставлять скрипту актуальную информацию. Даже если в какой-то момент мы удалим кластер postgresql14 и создадим новый с таким же именем, нам ничего не потребуется менять в коде Terraform. Источник данных dbcluster будет по имени получать актуальную информацию о новом кластере.
Выводы
Источники данных — это необходимый инструмент, если управлять инфраструктурой через Terraform приходится только частично, а другая часть инфраструктуры недоступна для управления.
Каждый провайдер Terraform предоставляет перечень источников данных, которые можно использовать для получения информации о ресурсах провайдера. Если у нужного нам объекта есть Terraform-провайдер и соответствующий источник данных, мы можем при выполнении операций Terraform запрашивать информацию об этом объекте и использовать ее в настройке нашей инфраструктуры.
Так мы можем получать информацию о виртуальных машинах, кластерах БД, сетях, DNS-записях и других ресурсах, которые не описаны в нашем проекте Terraform.
Область применения источников данных этим не ограничена. Например, существуют специальные источники данных, которые могут использовать для получения информации сторонние tfstate. Есть источники данных, которые умеют работать с локальными файлами и архивами. С помощью источников данных вполне возможно организовать управление секретами Terraform.
Главное в источниках данных — они позволяют в проекте Terraform получать актуальную информацию о состоянии внешних для инфраструктуры объектов и использовать эту информацию в нашей инфраструктуре.
