JS: Последовательности
Теория: Отображение списков
Отображение списков — пожалуй, самая популярная операция, которая происходит в программировании. В языках она обычно представлена функцией map.
Например, в функциональных языках map — это самая часто используемая функция, которая встречается буквально через строку. Но и в таких языках, как JavaScript, Python, Ruby, даже в последнее время PHP и Java, не говоря уже о более новых языках, программисты крайне часто используют данный метод. Обычно map целиком и полностью заменяет необходимость использовать циклы, что является неоспоримым преимуществом.
Давайте познакомимся с отображением списков на примере конкретной задачи.
В данном примере мы формируем html-структуру, которая содержит в себе 2 тега blockquote (это цитаты). Ниже можно увидеть, как они добавляются в HTML. При этом мы сразу создаём этот HTML с помощью make. Далее с помощью функции b2p, которая принимает на вход HTML и возвращает новый HTML, заменяем теги blockquote на p.
Ниже распечатан processedHtml и демонстрируется результат замены:
Данная операция может происходить в реальной жизни. Давайте посмотрим, как устроена внутри функция b2p:
Здесь происходит классический рекурсивный процесс, нужно только увидеть ключевые точки. Мы получаем голову от списка, производим какие-то преобразования и в самом конце делаем рекурсивный вызов функции b2p в которую передаём хвост.
Данный рекурсивный процесс, постепенно углубляясь во внутрь, сформирует вложенные cons и у нас получится список в котором blockquote заменены на p.
В примере выше можно увидеть одну проблему. Она связана с тем, что нам важно знать о том, что из себя представляют элементы, чтобы их обходить. Это означает, что нам пришлось бы переписывать все функции для обработки HTML именно из-за того, что нам нужно знать, что внутри у нас список. Если бы вышла новая версия этой библиотеки и там использовались бы не функции head/tail, то весь код пришлось бы переписывать. Этот отрицательный момент связан с тем, что функций может быть очень много и это не обязательно замена одного тега на другой (хотя и количество таких вариантов может быть велико). В реальной жизни у элементов существует ещё и большое количество атрибутов. Возможно мы захотим извлечь их значения. То есть не обязательно получить на выходе HTML. На выходе мы можем получить список чего-то, например, ширины элементов и найти самый широкий из них для того, чтобы произвести какие-то манипуляции. Количество задач с использованием этого подхода бесконечно, можно проходиться по всем элементам и формировать новый список или структуру на их основе, в которой мы, например, преобразовали какие-то элементы.
Отображение последовательностей
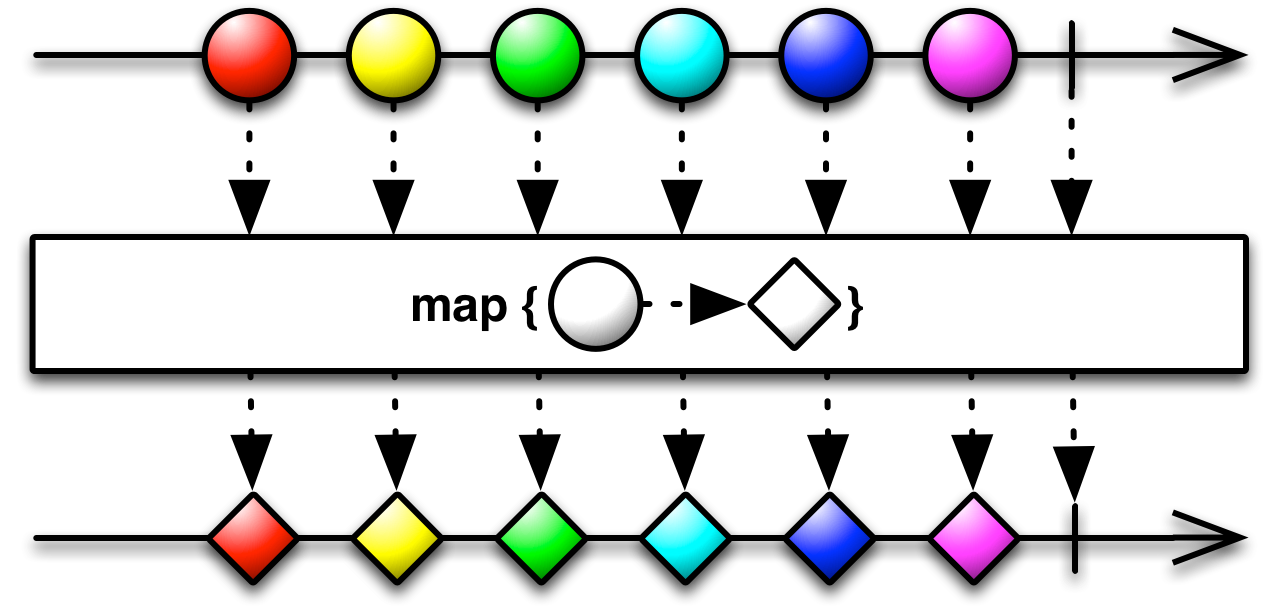
Map (отображение) — универсальная абстракция. В каждом языке есть перечислимые типы данных: например, массивы или списки, и для них почти наверняка есть встроенная функция map. Она работает всегда одинаково. Принимает на вход коллекцию и функцию-трансформер, которая берет элемент и возвращает его преобразование (конкретное действие зависит от конкретной ситуации). Различается только способ вызова и иногда порядок аргументов. То же самое касается и любой абстракции, построенной поверх коллекций. Все, что может быть перечислено, может быть отображено. Неизменным в этих отображениях всегда остается количество элементов. Отображенная коллекция элементов всегда такого же размера, как и исходная.
Давайте посмотрим на реализацию той же задачи, в которой мы использовали функцию b2p. Только теперь мы это сделаем через map и увидим, как поменяется наш код:
Функция map импортирована из библиотеки @hexlet/html-tags. Она принимает на вход функцию-обработчик и коллекцию, т.е. наш HTML. При этом не важно, какая у него структура. Сейчас мы с этим разберёмся. Для простоты и чтобы не писать много кода, сформируем HTML одной строкой append(append(make(), bq1), bq2), сделав внутренние вызовы функций.
Теперь давайте посмотрим, что из себя представляет функция, которая передаётся в map первым элементом:
В этом и кроется ключ. Как минимум, сразу понятно, что map — это функция высшего порядка. Структура самой функции такова, что она принимает на вход один параметр, который является элементом и обрабатывается в данный момент, а тело — это всё, что вы хотите сделать с этим элементом, абсолютно любой код. Главное, что в конце из этой функции вы должны вернуть нечто новое, что попадёт в результирующий список, который получится на выходе из map.
После этого мы получаем processedHtml, значение для которого возвращает map. Теперь, если распечатаем processedHtml с помощью toString, то увидим, что произошла замена:
Блок blockquote был заменён на p, также как это было в предыдущем примере.
Преимущества
- Универсальный код
- Декларативный код
- Абстрагирование от структуры
Давайте посмотрим, какие преимущества даёт нам использование map. Во-первых, мы получили универсальный код. Что это означает? Теперь решена проблема, заключавшаяся в том, что нам надо написать 500 000 одинаковых функций, которые делают немного разные преобразования, а потом ещё и рефакторить (переписывать) их, если поменялась внутренняя структура нашего HTML, т.е. мы как-то по-другому его реализовали. map, в данном случае, единая функция, которая специфицируется правильным поведением в зависимости от разных ситуаций, теперь можно не писать дополнительные функции, а просто каждый раз делать ту обработку, которая вам нужна.
Во-вторых, это декларативный код, взгляните на пример. Хотя там используются ещё не изученные нами вещи, он достаточно прост, чтобы понять концепцию.
[1, 2, 3] — это так называемый массив, но в данном случае мы будем говорить список, потому что можно воспринимать его как список. На первой строке показан принцип отображения. Был список [1, 2, 3], а стал [10, 20, 30]. Каждый элемент мы умножили на 10.
Давайте посмотрим на два возможных решения. Сразу оговорюсь, это реальный код, именно так пишут на JS. Это не пары и не то, что мы сейчас проходим и изучаем, потому что мы учимся, а то, как происходит по-настоящему.
Первое — это функциональный стиль с использованием отображения списков. К списку применяется функция map, которой внутри передаётся лямбда (анонимная функция) — x => 10 * x. Она принимает элемент и умножает его на 10. Причём возврат мы здесь не пишем, это сокращённый вид функции, которая в конечном итоге делает возврат этого значения. Думаю, очевидно, что здесь происходит, это очень лаконичный и выразительный код.
Но если мы посмотрим на пример, написанный в императивном стиле, обычный способ решения этой задачи, который реализуется через циклы, то видно, что кода стало больше.
Здесь присутствует изменение состояния и код не отражает суть операции, т.е. это просто последовательность шагов: берём это, кладём сюда, делаем то, делаем это.
В чём выражается декларативность? Код можно воспринимать, как определение нового списка. Список [10, 20, 30] в терминах нашего отображения — это исходный список, в котором каждый элемент умножен на 10. По сути, данное определение — это спецификация. Имплементацией этого отображения является запись [1, 2, 3].map(x => 10 * x);. Здесь нет изменяемого состояния, что является обязательным для декларативного кода. Как вы помните, это избавляет нас от большого количества потенциальных ошибок.
И третий немаловажный момент — это абстрагирование от структуры. Напомню проблему. Когда мы работаем императивно или пишем сами функции обхода нашей структуры, то мы обязаны знать, как эта структура устроена внутри. Если такого кода очень много, то при любом изменении самой структуры вам придётся переписывать почти весь код. Но в данном случае мы переходим на новый уровень абстракции. То есть map строит барьер абстракции, удаляя нас от деталей того, как реализовано то, с чем мы работаем. Поэтому за map может скрываться всё, что угодно. Деревья, множества, какие-то сложные вещи, которые не так просто обходить, но можем об этом уже даже не задумываться.
Ниже еще пара примеров работы с использованием map. Взгляните как элегантно можно извлечь квадратный корень из элементов списка:
Теперь давайте посмотрим, как реализуется map:
Если мы вспомним первую функции b2p она была длиннее и сложнее устроена. Здесь мы видим почти то же самое, кроме одного аспекта. В том месте, где мы получаем новый элемент newElement, мы не самостоятельно как-то его обрабатываем, а используем для этого функцию func, которая передаётся первым параметром в map. Мы просто применяем функцию к элементу и после этого мы передаём эту функцию в следующий map, который рекурсивно вызывается для хвоста списка. Таким образом он постепенно обходит все его элементы, формируя рекурсивный процесс, и в конечном итоге получается отображённый список.
