JS: Последовательности
Теория: Стандартные интерфейсы
Хорошая абстракция даёт нам много разных преимуществ. Одно из которых — это увеличение модульности программы. Выражается это в том, что разные куски кода нам гораздо проще комбинировать и, имея небольшой набор базовых функций и компонентов, мы за счёт их сочетания можем получать гораздо более сложное поведение и строить любые конструкции.
В реальной жизни мы с этим тоже встречаемся очень часто. Знакомый всем пример, который отражает эту идею — конструктор Lego. Этот принцип называется — использование стандартных интерфейсов. Практически все детали в этом конструкторе сделаны таким образом, что они друг с другом комбинируются разными способами. Всё это работает благодаря тому, что все детали содержат пипочки, которые расположены на одинаковом расстоянии друг от друга. И вы можете их соединять как угодно. Это отличный пример и приём, который показывает то, как, используя небольшой набор базовых компонентов, можно строить действительно сложные вещи.
Есть другие конструкторы, где большое количество деталей уникально, и в конечном итоге вы не сможете их особо комбинировать. Всё, что вы сможете сделать с такими конструкторами, строить заранее продуманные решения, которые предполагались для сборки производителем.
В программировании, по крайней мере в том, что мы уже знаем и продолжаем изучать, такими стандартными интерфейсами являются списки. Наши функции, в особенности функции высшего порядка, занимаются тем, что принимают на вход списки и выдают на выходе чаще всего также списки. Что очевидно позволяет выстраивать их в цепочки и получать достаточно сложное поведение.
Определение частоты слов в заголовках
| Обучение | 3 |
| Практика | 2 |
| Онлайн | 1 |
| Хекслет | 1 |
Давайте рассмотрим достаточно простую задачу: вычислить частоту слов в заголовках. В результате должна получиться таблица, как в примере выше. Предположим, у нас есть HTML, в котором есть разные заголовки. И мы хотим посмотреть, какие слова в них наиболее часто встречаются. Это вполне реальная задача. Она часто возникает в различных инструментах для маркетинга в SEO-направлении, которые анализируют правильно ли составлены страницы и дают рекомендации по улучшению.
Монолитное решение
- Цикл/Рекурсия
- Один проход
- Все действия сразу
Монолитное решение заключается в том, что в один проход будет выполнен цикл, либо рекурсия. С какой-то стороны это эффективно, потому что проход всего лишь один. Все действия выполняются сразу, они разбросаны по коду. И даже если мы по спецификации представляем это всё, как независимые куски, когда выборка слов — это несколько разных этапов, о которых мы сейчас поговорим, то здесь все эти этапы будут перемешаны. Невозможно будет взглянув на решение, сразу разобраться, что в нём происходит. Его нужно анализировать и понимать всё целиком, что может быть достаточно сложно.
Разделение
- Фильтрация (оставляем только заголовки)
- Отображение (извлекаем текст)
- Свертка (компонуем текст)
- Свертка (строим результирующую таблицу)
Если применять подход стандартных интерфейсов, то можно увидеть, что эта задача, да и большинство задач, которые мы встречаем в разработке, может быть выражена через такие простые действия, как фильтрация-отображение-свёртка и множество других более специфических. Наша задача может быть разделена на четыре этапа:
- Фильтрация. Оставляем только заголовки. Наш фильтр принимает на вход список и возвращает список.
- Отображение. Извлекаем из заголовков текст. Опять же принимает и возвращает список, который уже содержит не теги, а текст.
- Свёртка. Мы компонуем текст, и на выходе получается один большой массив текста, в котором возможно сразу будут выделены слова.
- Повторная свёртка. Проходим по этим словам, подсчитываем их количество и строим результирующую таблицу.
Это решение в коде выглядит абсолютно также, как мы его описали в тексте. Сначала мы делаем filter. На вход приходит html, из него мы достаём только заголовки. Код очень декларативный, понятный, и спецификация восстанавливается по нему очень просто. После этого делаем map (отображение), посредством которого мы извлекаем значение из каждого тега, полученного на предыдущем этапе. Далее отдаём эти значения в reduce. Начальным аккумулятором он принимает список l(). И внутри него мы вызываем функцию addWords, которая добавляет все слова в аккумулятор. values на этапе, когда срабатывает reduce, это массив текста, т.е. просто строчка из заголовков. Естественно, их нужно разбить и добавить в аккумулятор, чтобы в итоге у нас получился список из слов.
Внутреннее устройство функции addWords мы не приводим, чтобы не отвлекаться от сути. Она работает по такому же принципу: разбивает текст на слова и добавляет по слову в аккумулятор с помощью внутреннего reduce. В конечном итоге мы получаем список всех слов words. Слова, естественно, могут и должны дублироваться.
После этого делается ещё один более сложный reduce, который идёт по всем словам, убирает дубли и инкрементирует счётчик каждого слова, которое повторяется. В конечном итоге мы также получаем список слов, которые содержит количество вхождений каждого из них в заголовки.
Стандартные интерфейсы
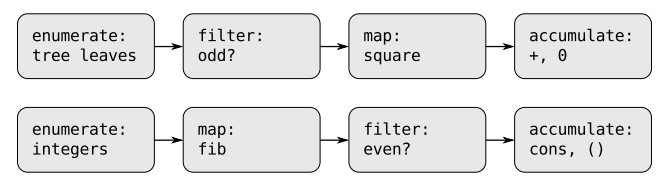
Теперь мы видим, что стандартные интерфейсы — это отличное решение, которое даёт нам несколько важных преимуществ.
- Увеличивают модульность.
- Упрощают понимание. Программа разбивается на множество последовательных независимых кусков, которые могут анализироваться и восприниматься самостоятельно.
- Унифицируют вычисления. Программисты, владеющие этими выразительными средствами, создают такие программы, которые действительно очень легко читать. Они очень хорошо разбиваются на элементы. И эта унификация позволяет вам легко анализировать достаточно большие куски кода и без проблем дописывать их самостоятельно.
