Python: Numpy
Теория: Многомерные массивы в Numpy
Библиотека Numpy дает мощный и удобный высокоуровневый аппарат для работы с многомерными данными. Для работы с ними в Numpy разработана своя собственная структура данных — массив numpy.ndarray. Именно под эту структуру оптимизирована работа всего функционала библиотеки.
В этом уроке познакомимся с тем, как создавать массив ndarray из стандартных типов данных языка Python и попробуем на практике решить ряд простых аналитических задач.
Структура данных библиотеки Numpy
Чтобы создать структуру numpy.ndarray, нужно конвертировать список list. Для конвертации из множества set требуется дополнительное приведение типа данных.
Рассмотрим на таком примере:
А теперь разберем этот код подробнее. Сам пример показывает встроенную функциональность для создания структуры numpy.ndarray. Мы импортируем библиотеку Numpy, создаем короткий список значений simple_list, а затем конвертируем в массив my_first_ndarray. Для этого вызываем конструктор np.array() с объектами для конвертации.
С учетом примера выше, обратная конвертация в список происходит так:
Конвертация из списка Python — это самая популярная операция, с помощью которой создается структура numpy.ndarray.
Так происходит потому, что обмен данными между функциями и сервисами удобно производить в стандартных структурах данных языка. Другими словами, можно не вводить структуры данных сторонних библиотек и не усложнять программу.
Но при разработке сложных программ модуль numpy.ndarray может быть только частью общей структуры. В таких случаях используют стандартные типы данных языка для обмена данными между функциональными частями программ.
В итоге порядок работы с данными при работе с Numpy выглядит следующим образом:
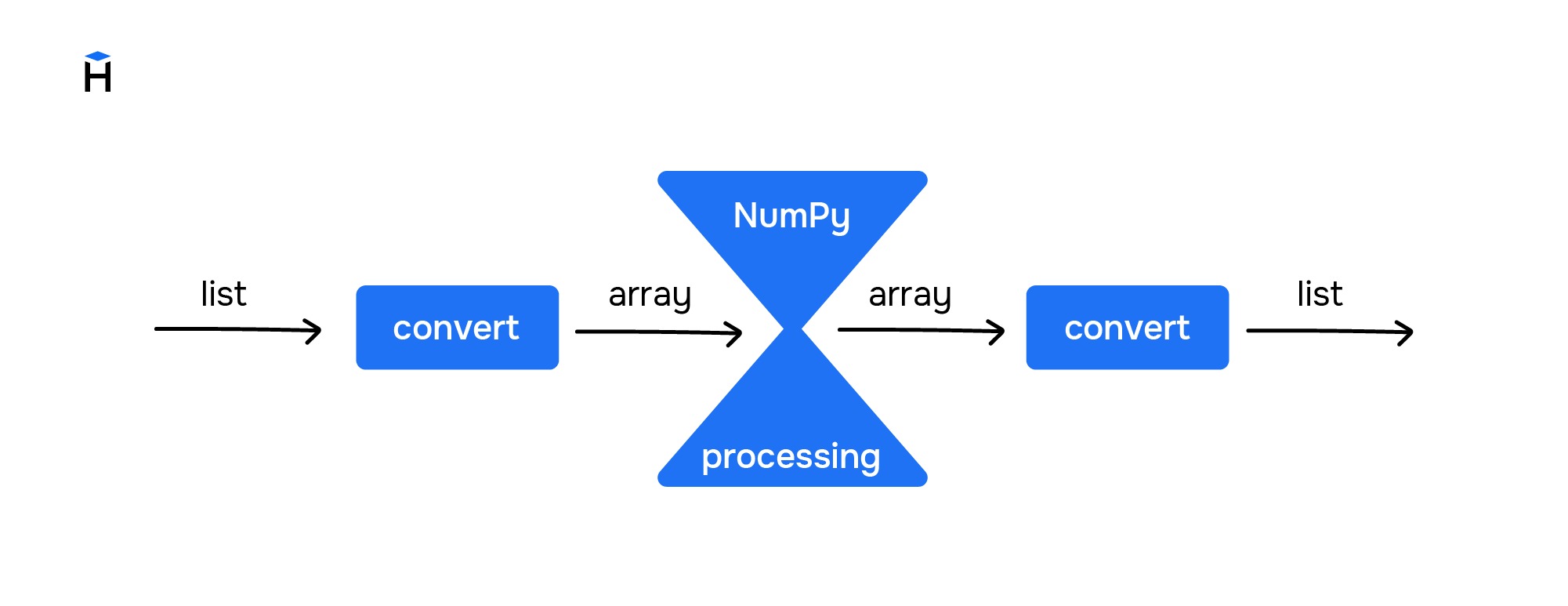
Как правило, вычислительные и аналитические модули в виде входных данных ожидают списки значений. Всю оптимизацию они делают уже внутри себя в собственных абстракциях, невидимых извне. Это сделано для простоты интеграции.
Допустимые типы данных
Поговорим подробнее о типах элементов массива, которые можно использовать для numpy.ndarray. Продолжим работать с тем же примером и воспользуемся следующим методом:
Как и ожидалось, тип данных — int64. Необязательно ограничиваться только им:
Обратите внимание, что для экземпляра структуры numpy.ndarray нельзя использовать сразу несколько типов данных. Проще говоря, все элементы в массиве должны быть однотипные. Посмотрим, как конструктор сам определит тип данных при конвертации:
Заметим, что ошибки при конвертации смешанного типа элементов массива не произошло. Конвертор просто привел все данные к строковому типу.
Как Numpy работает на практике
Функциональность библиотеки Numpy настолько интуитивна, что уже сейчас можно решить простую аналитическую задачку.
Представим продажи ноутбуков в магазине за одну неделю:
На практике такие данные обычно хранятся в табличном виде в базе данных. Чтобы упростить пример, мы пропустили этап выгрузки — подразумевается, что данные приходят в вычислительный модуль уже в виде списка значений.
Поработаем с данными с помощью библиотеки Numpy:
Попробуем найти день недели с самыми низкими продажами. Опыт работы с Python подсказывает, что метод будет называться min() или minimum(). Найдем минимальное количество продаж и заодно день недели, в который оно совершено:
Чтобы найти наибольшее количество продаж, достаточно поменять одну функцию:
На практике часто анализ не ограничивается только одной неделей продаж и одним магазином. В этом случае набор данных представлен в виде списка списков элементов — это уже двумерная структура, которая в математике называется матрицей.
В Numpy реализация инициализации массивов и функций работы с ними не зависит от размерности данных, что существенно упрощает разработку.
В современных библиотеках можно применять одну и ту же функцию к различным типам данных. Рассмотрим это на примере, похожем на предыдущий. Найдем день с самыми низкими доходами во всей сети магазинов. Рассмотрим недельные продажи в четырех магазинах:
Мы ожидаем, что функционально все должно быть реализовано похожим образом. Давайте в этом убедимся, взглянув на код:
В приведенном примере метод min() находит минимальный элемент среди всех значений массива.
Большинство функций в Numpy реализованы так, что методы и функции выполняют одинаковые операции, вне зависимости от типа данных на входе.
В программировании такой подход называется полиморфизмом. Он упрощает разработку и делает код более простым для анализа и поддержки.
Выводы
Сегодня мы познакомились с основной структурой данных библиотеки Numpy — массивом numpy.ndarray.
В работе с ним мы используем указанный тип данных — это обусловлено оптимизацией работы функций внутри библиотеки. У Numpy понятный интерфейс для конвертации типа данных list из стандартной библиотеки Python.
Новые знания мы сразу закрепили на практической задаче — вычислили день с самыми низкими доходами в сети магазинов. Эта задача показывает, насколько Numpy упрощает работу с входными данными разной размерности.

