Продакшен и Деплой
Теория: Мониторинг
Если проект работает в продакшене прямо сейчас, это не значит, что он не перестанет работать завтра. Почему? Существует масса причин, почему все может пойти не так:
- На сервере закончится место на диске.
- Выйдет из строя любая часть серверной инфраструктуры.
- Возрастет нагрузка, и сервер перестанет справляться с входящими запросами.
- Количество данных в базе увеличится до такой степени, что запросы начнут выполняться слишком долго.
- Проявятся ошибки, которые не нашли во время тестирования.
Ни одной из этих проблем нельзя избежать, даже если купить самое дорогое оборудование и нанять большую команду тестировщиков. Ошибки и сбои происходят регулярно у всех, а вот скорость их обнаружения и починки зависит от того, как настроен мониторинг.
Мониторинг неотъемлемая часть любого проекта, который помогает быстро обнаруживать неполадки и устранять их. Он включает в себя три основных элемента:
- Сбор метрик, например, анализ оставшегося места на диске или проверка кодов ответов веб-сервера.
- Визуализация метрик, возможность посмотреть их на графике, поискать корреляции между разными показателями.
- Оповещение (Алертинг) об ошибках или опасных ситуациях.
На базовом уровне, мониторинг есть в любом облаке. Для готовых сервисов типа балансировщика нагрузки или очереди, облака дают полный спектр метрик, какой только себе можно вообразить. Для серверов, мониторинг включает в себя информацию о загрузке процессора, потреблении оперативной памяти, сетевому трафику и нагрузке на диск. Этих метрик может быть недостаточно, если нужен тонкий контроль происходящего. Кроме того, на сервера ставятся программы, которые сами требуют мониторинга. Например для веб-сервера нужно, как минимум следить за количеством входящих запросов и ответами.
Сбор метрик
Откуда берутся данные для графика? Система мониторинга получает их от агента, специальной программы, которая установлена на сервер и собирает информацию о системе. Конкретно Digital Ocean, умеет устанавливать агент автоматически при создании сервера. Агенты внешних систем мониторинга придется ставить самостоятельно, например, с помощью Ansible.

Независимо от способа установки, все агенты работают примерно одинаково. Они получают данные от операционной системы или запущенных на ней программ и отправляют их в центральное хранилище. Получение данных происходит двумя способами: вытягиванием данных или приемом входящих данных.
В большинстве ситуаций предпочтительно вытягивание, так как его контролирует сам агент. Он извлекает нужную ему информацию от системы или приложений. Сюда входит масса различных вариантов взаимодействия: периодическое чтение файлов, запуск программ возвращающих нужные данные, http-запросы, например, в случае Nginx, который отдает специальную страницу с информацией о происходящем внутри него.
В большинстве систем мониторинга, агенты поставляются с готовыми интеграциями, либо расширяются сторонними решениями, которые знают как извлекать данные из приложений. А если такой интеграции нет, то всегда можно написать свою проверку.

В такой модели работы важно смотреть на интервал опроса. Чем он меньше, тем быстрее и точнее мы получаем информацию, но при этом нагрузка на систему возрастает, чем он больше, тем меньше точность, но меньше нагрузка на систему. Как ориентир можно смотреть на интервал в 15 секунд, но учитывайте, стоимость сервисов мониторинга часто зависит от скорости опроса.
Вывод графиков
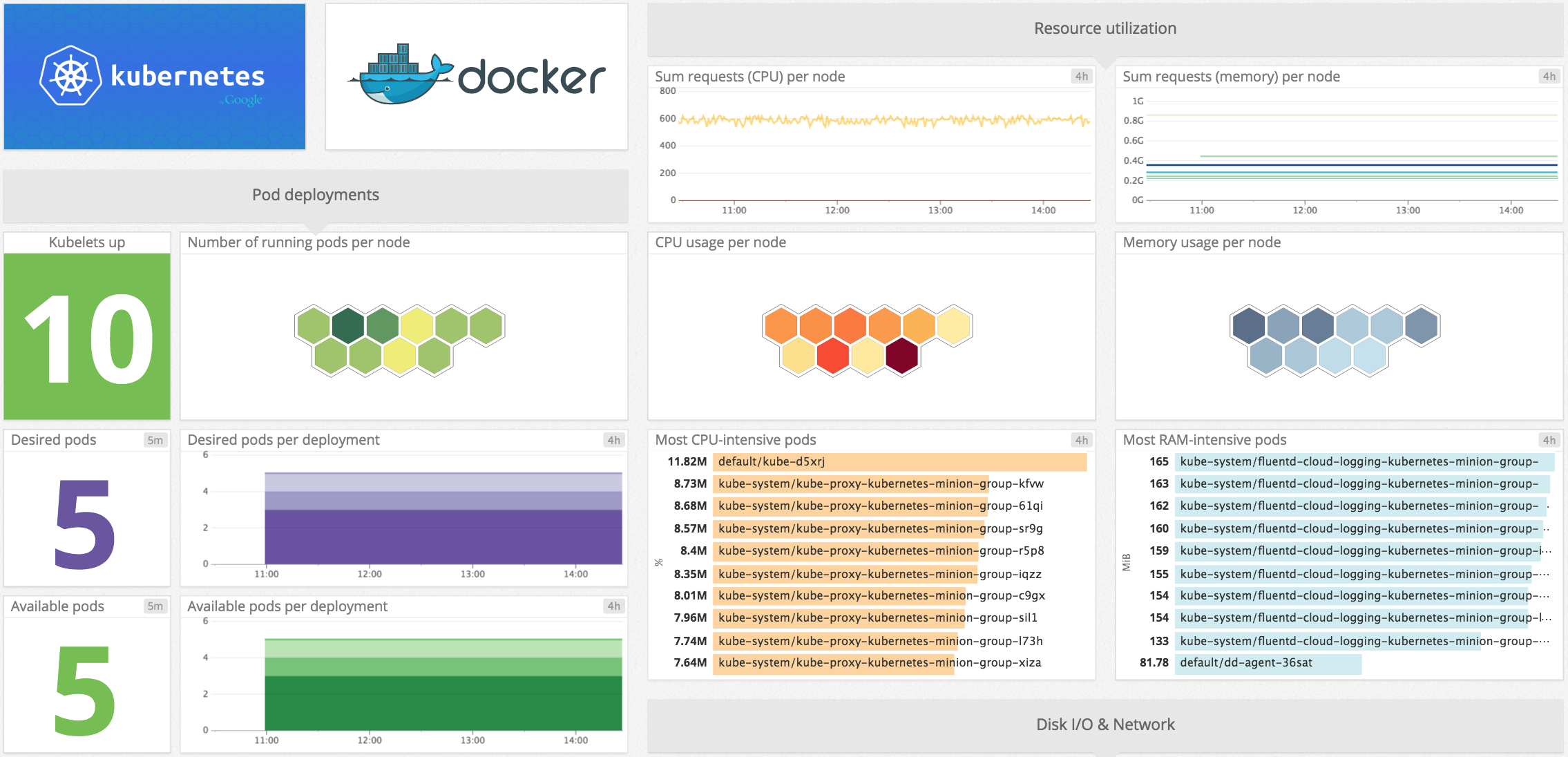
Как только данные начинают поступать в сервис мониторинга, их сразу можно выводить на графиках. Благодаря готовым интеграциям, эти сервисы знают о том какие метрики и как собираются, поэтому часть графиков уже готова и, даже, объединена в дэшборды. Пример дэшборда Kubernetes в DataDog:
Алертинг
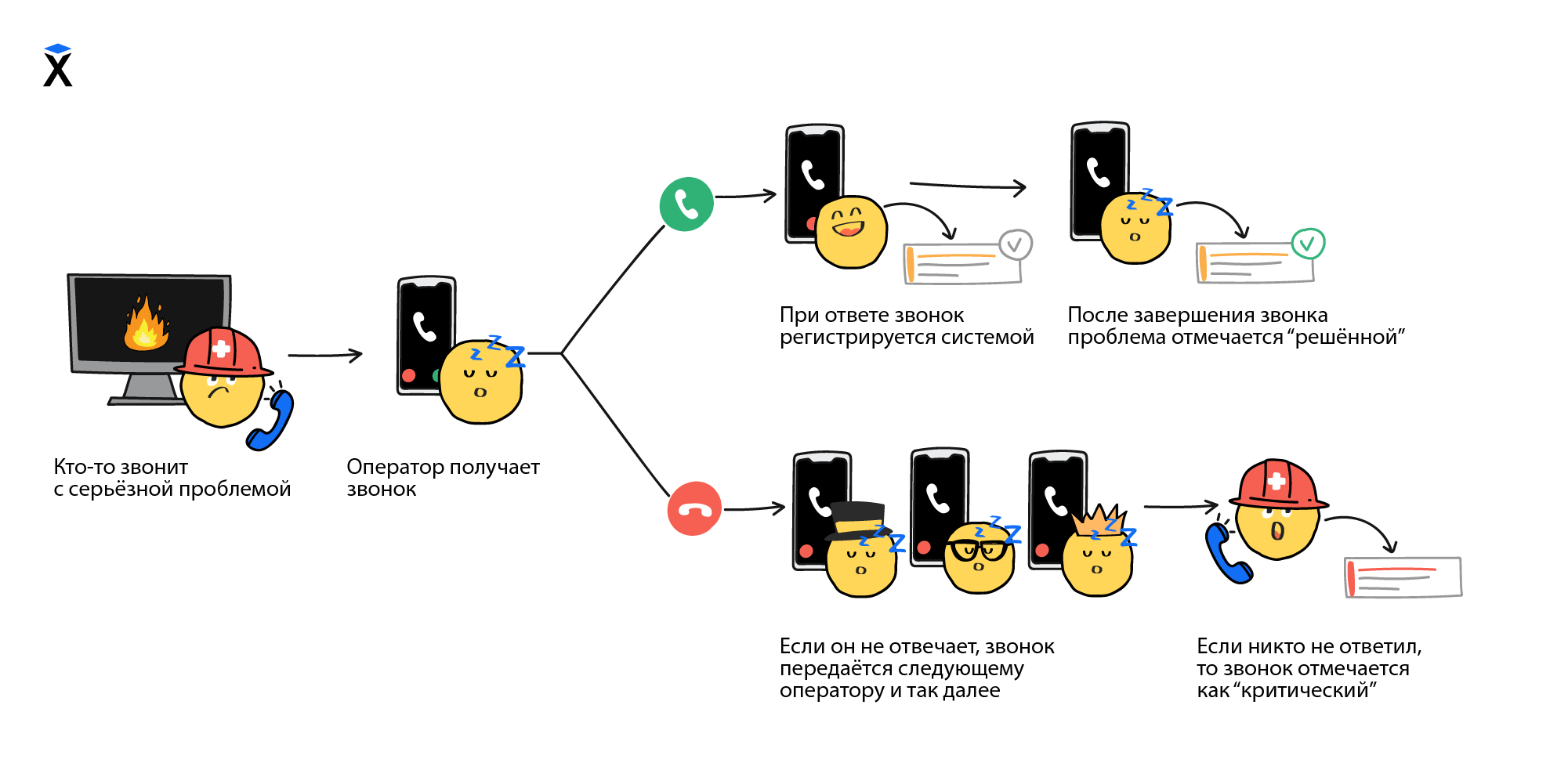
Наличие графиков полезно, когда мы уже знаем о проблеме и пытаемся в ней разобраться, но они не помогают узнать о существовании проблемы, пока мы на них не смотрим. Для оповещений нужно настраивать алерты. Каждый алерт следит за какой-то метрикой и срабатывает в том случае, если ее значение отклоняется от допустимого.
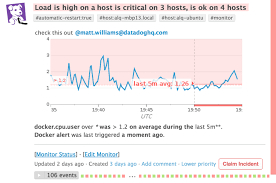
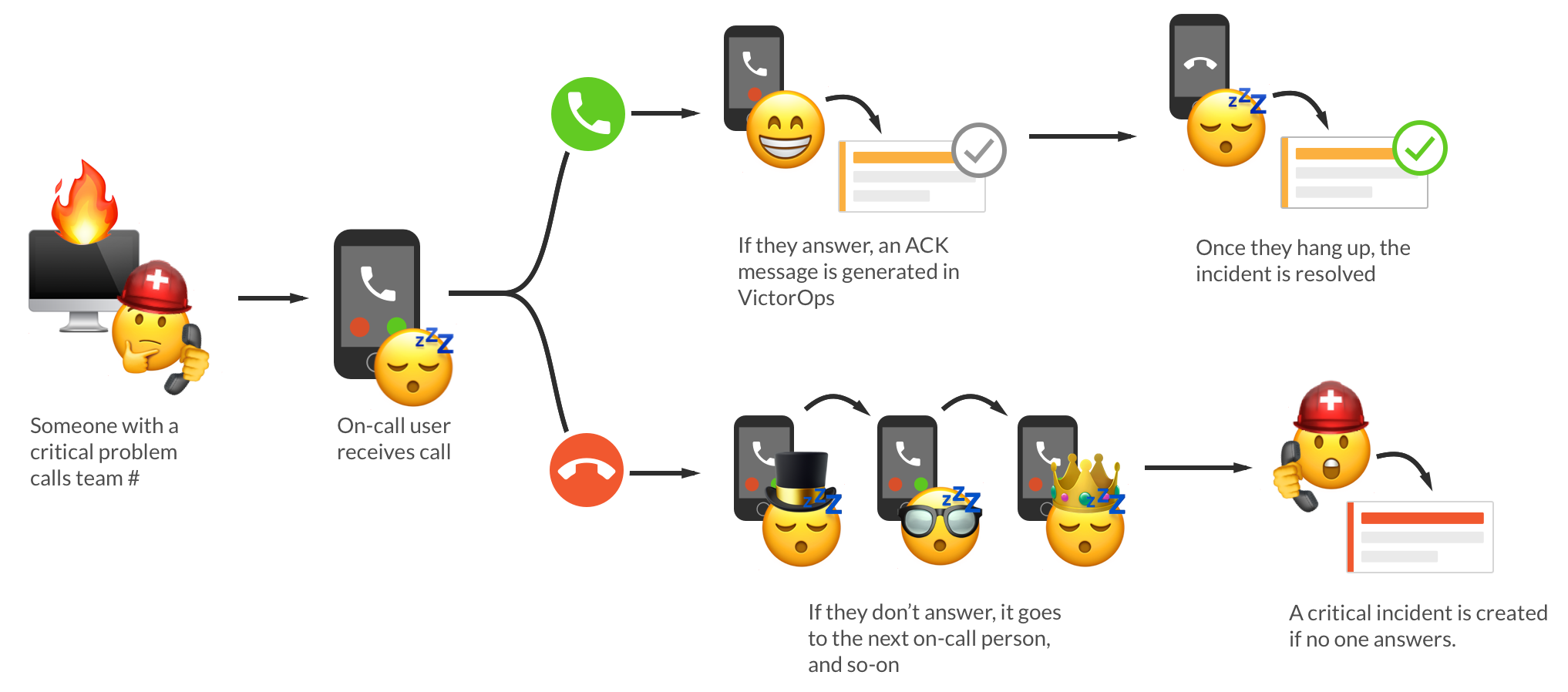
Оповещение о проблемах может происходит разными способами от сообщений в слаке до смс. Существуют даже специальные сервисы, которые настраивают правила оповещения команды в порядке дежурства до тех пор, пока кто-то не откликнется.
Интересно то, как алерты создаются. Представьте себе задачу отслеживания нагрузки на процессор. Если она высокая, то нужно разобраться почему и, в случае необходимости, добавить новый сервер. Кажется, что достаточно установить алерт на превышение порога нагрузки на процессор, например, в 80%. То есть если нагрузка на процессор выше 80%, то уходит оповещение. Звучит просто, но такой способ не приведет ни к чему хорошему. Нагрузка имеет свойство скакать. В течение дня она не раз может прыгать выше 80%, но большую часть времени не превышать 40%. В итоге слак будет завален сообщениями о несуществующих проблемах. Примерно то же самое можно сказать и про любую другую метрику. Что бы мы не отслеживали, пиковые значения всегда могут превышать норму. Как тогда быть?
Алерты создают по двум основным схемам:
- Количество срабатываний в течение какого-то периода. Например, количество 500 ошибок, которые отдает веб-сервер. Одна ошибка в минуту, может быть случайностью, но 100 штук в течение минуты уже проблема.
- Выход за границу допустимого порога в течение определенного промежутка времени. Например, непрерывная нагрузка на сервер выше 80% в течение 5 минут.
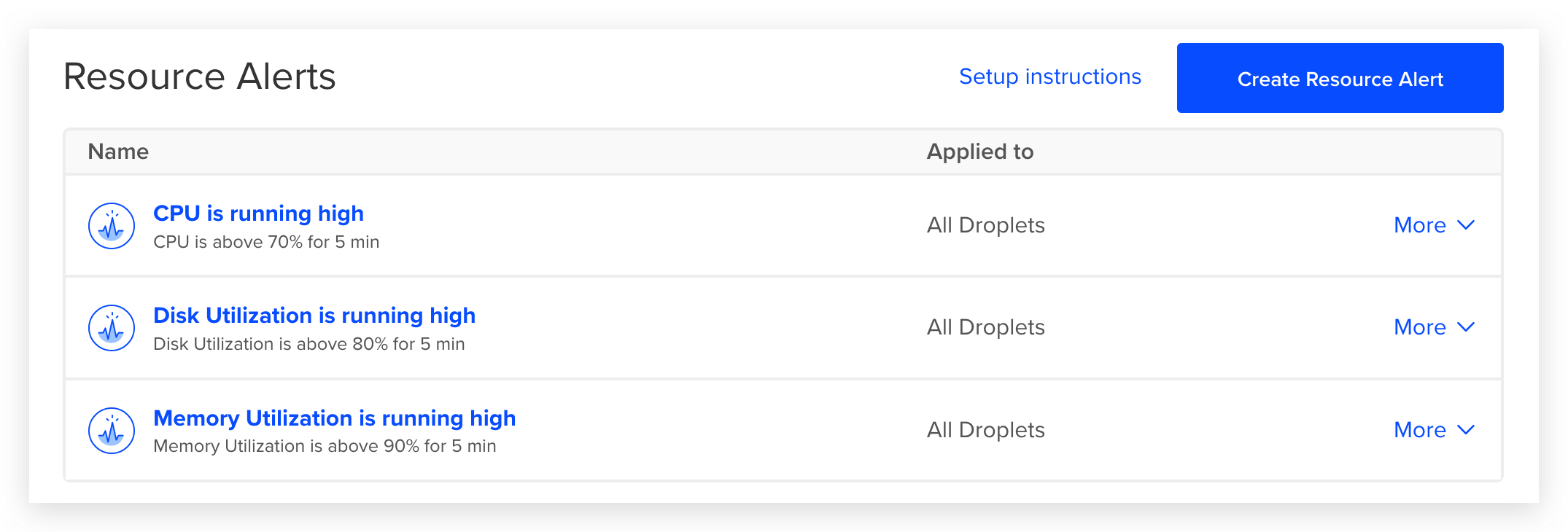
Насколько такая настройка точная и гарантирует наличие или отсутствие проблемы? К сожалению, не существует способа точно определить когда проблема есть, а когда ее нет. Конечно же существуют практики того, как лучше настраивать алерты, но, по большей части, все зависит от конкретной системы, нагрузки на нее, интервале опроса и других параметров.
Главное в работе с алертами - реакция. Если алерты настроены плохо и срабатывают тогда, когда реакция не нужна, они быстро превращаются в белый шум, на который никто не обращает внимание. Становится легко пропустить что-то действительно важное. Алерты должны срабатывать только тогда, когда на них требуется реакция. Это требует постоянного добавления, удаления и настройки существующих алертов.
Self-Hosted решение
В тех случаях, когда готовый сервис мониторинга использовать не получается или нельзя, для мониторинга пользуются готовыми открытыми проектами. Сюда входят две системы:
- Prometheus - для сбора метрик и алертинга
- Grafana - для вывода графиков
