Docker
Теория: Слои, кеширование и оптимизации
Одна из ключевых концепций в работе Docker связана с тем, как устроена его файловая система и какие преимущества из этого следуют. В этом уроке мы познакомимся с понятием слоев, их кешированием и гарантией повторяемости.
Большинство Docker-образов содержащих готовые приложения, весят от сотен мегабайт до нескольких гигабайт. Это значит, что стартуя контейнер, вся эта файловая система должна копироваться куда-то, чтобы с ней можно было работать, добавлять, изменять и удалять файлы. Старт контейнера, в таком случае, мог бы занимать десятки секунд и даже минуты. Однако, этого не происходит. Docker значительно оптимизирует эту часть работы за счет использования файловой системы OverlayFS.
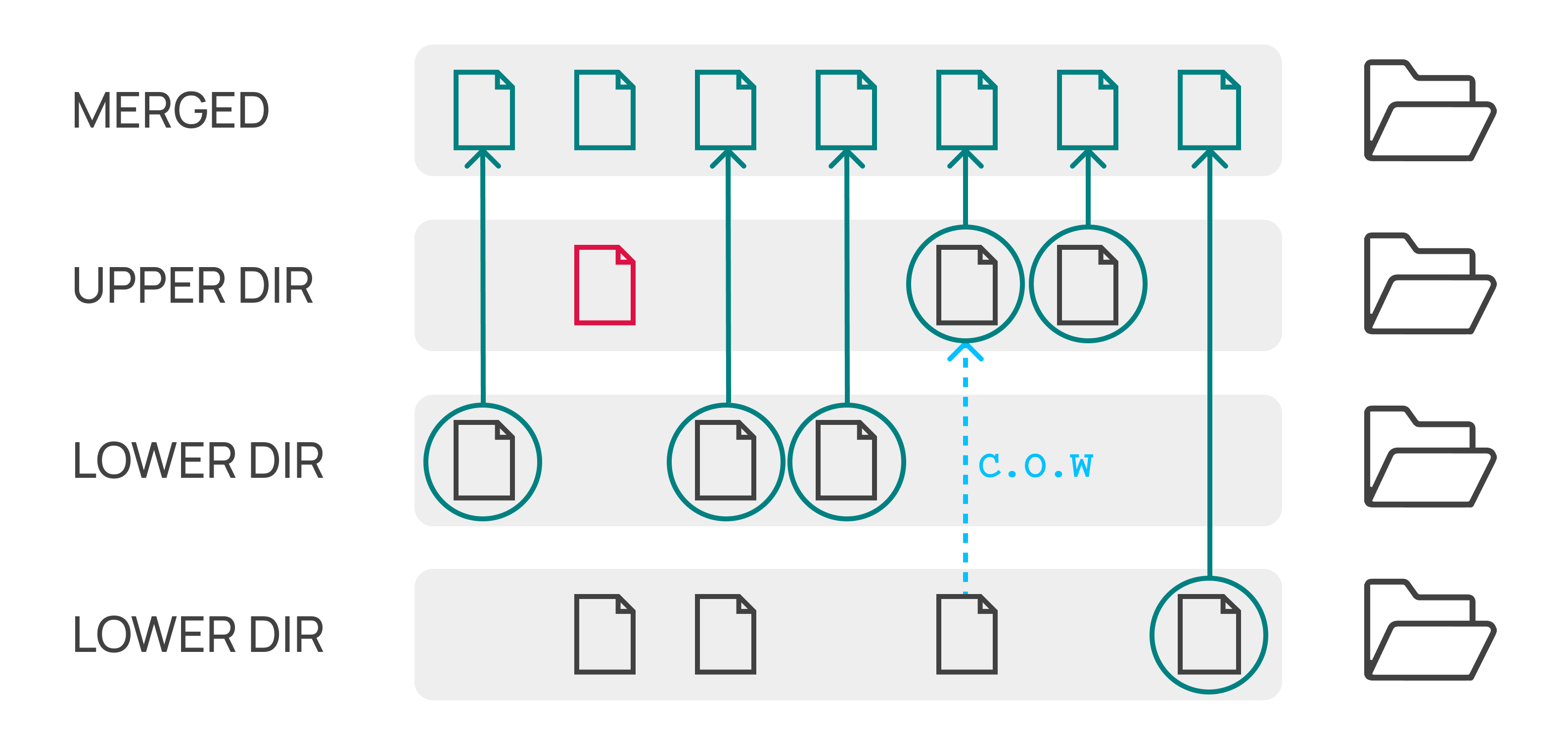
Принцип ее работы следующий. OverlayFS работает не с единой файловой структурой, а c частями, которые называются слоями. Каждый слой, это набор файлов и директорий, получающийся в результате выполнения команды RUN и ей подобных внутри Dockerfile. Затем слои виртуально сливаются в одну структуру, создавая внешнее впечатление что все эти директории и файлы находятся в одном месте.
OverlayFS
Проще всего понять эту концепцию на примере. Возьмем такой Dockerfile:
Во время сборки, Docker отслеживает изменения файловой системы и если они произошли, то эти изменения хранятся отдельно, не трогая то, что было до них. То есть где-то внутри всё, что поменялось, хранится как отдельный набор файлов. Количество изменений файловой структуры в рамках одного слоя не ограничено, измениться может как один файл, так и вообще все.
В примере выше есть только добавление файлов и директорий. В таком случае каждый следующий слой соответственно содержит то что было добавлено именно в нем. Но что будет если файл меняется или удаляется? Ровно то же самое, предыдущие слои не могут поменяться, а это значит что измененный файл будет продублирован в том слое где его поменяли, а удаленный просто помечается как удаленный, так как его физически нельзя удалить, он уже был добавлен в предыдущих слоях. Из-за этого размер образа не будет уменьшен после удаления файла, который был добавлен в другом слое:
В данном случае удаление просто скрывает этот файл, так как более поздний слой "накладывается" на предыдущий. Но физически, файл находится внутри и занимает место.
Все это относится не только к текущему Dockerfile, но и ко всей иерархии образов вплоть до базового образа scratch. В этом смысле принцип формирования Docker-образов очень похож на то, как работает Git. Образы в этом смысле выступают просто ветками, которые никогда не сливаются.
Для того чтобы эта система работала прозрачно, каждый следующий слой видит предыдущие как объединенную файловую систему без разбиения на слои. Поэтому с точки зрения работы с Docker создается ощущение, как будто нет никакого OverlayFS. Это легко проверить если запустить любой контейнер и поменять файлы внутри. У Docker есть команда docker diff, которая показывает изменения сделанные в рамках работы с контейнером:
Очень похоже на git status. Только в отличии от Git, внутри хранятся не изменения а файлы целиком.
Что все это дает? Довольно много. Фактически полностью пропадает необходимость копировать файловую структуру при старте контейнера. Любые изменения сделанные внутри, не меняют исходную структуру файлов, они создают новый слой, который уничтожается при удалении контейнера. Как плюс, значительно сокращается место занимаемое запущенными контейнерами.
Кеширование слоев
Так как каждый слой не изменяет предыдущий, а формирует набор изменений, то Docker идет еще дальше и вычисляет хеш этих изменений, который становится идентификатором слоя. Такая схема позволяет сравнивать слои по хешам и не дублировать их содержимое. То есть, если например мы сделали два образа наследующихся от ubuntu у себя на машине, то образ ubuntu не будет существовать в двух вариантах. То же самое касается и команд внутри Dockerfile. Если два образа наследующихся от одного базового образа имеют общие команды в начале, то они получат преимущество по объему хранения, так как эти слои не будут дублироваться:
Выше мы видим что первые строчки в образах одинаковые. Поэтому они будут переиспользоваться. Это не только сокращает место, но и ускоряет сборку. Собрав один из этих образов, мы увидим, что второй начнет собираться с той команды, где начинается различие: RUN touch file3.
Иногда это создает проблемы. Предположим что у нас есть такой Dockerfile:
Если мы хотя бы раз собирали или скачали образ, то повторный запуск всегда будет переиспользовать существующий слой. Docker никогда не завязывается на внешние системы и не может проверить, что make мог обновиться. И это правильно, так как задача Docker обеспечивать повторяемость (идемпотентность). Чтобы заставить его игнорировать существующие слои и выполнить все команды заново, нужно добавить флаг сборки --no-cache:
Иногда, для лучшего контроля делают по-другому, например, добавляют дополнительную строку в Dockerfile, которая приводит к аналогичному результату:
Удобство такого подхода в том, что изменение фиксируется в Git.