Основы алгоритмов и структур данных
Теория: Алгоритмическая сложность
В программировании используются алгоритмы, которые по-разному решают одну и ту же задачу: например, сортировку массива. При этом алгоритмы работают с разной скоростью и требуют разное количество памяти. При прочих равных условиях мы бы выбрали быстрый или нетребовательный алгоритм.
Чтобы правильно выбирать алгоритмы, нужно научиться сравнивать их, чем мы и займемся в этом уроке. Мы познакомимся с двумя основными способами, разберем их плюсы и минусы. Опираясь на эти способы, мы сравним время работы уже знакомых нам алгоритмов.
Как оценить скорость алгоритма
Скорость алгоритмов можно сравнивать самым очевидным способом — физически измерить время выполнения на одних и тех же данных. Чтобы сравнить сортировку выбором и быструю сортировку, мы можем взять массив из нескольких элементов и измерить время быстрой сортировки:
Алгоритм быстрой сортировки мы уже разбирали. Единственное, что нам пока не встречалось — вызов метода performance.now().
Performance — это объект в глобальной области видимости, который используют для измерения производительности. Метод now() возвращает количество миллисекунд с момента старта браузера. Можно запустить этот метод, сохранить значения до запуска кода и после его завершения, и вычесть одно из другого — и тогда мы узнаем, сколько миллисекунд работал наш код.
Чтобы сравнить два алгоритма, надо упорядочить точно такой же массив с помощью алгоритма выбора:
Оценим скорость кода выше:
- Быстрая сортировка — 0,20 миллисекунд
- Сортировка выбором — 0,09 миллисекунд
Результат выглядит странно. Раз уж быструю сортировку назвали быстрой, то время ее выполнения должно быть меньше, чем у сортировки выбором. Здесь дело в том, что результаты однократного измерения ненадежны. Нужно измерить производительность алгоритмов несколько раз подряд на одних и тех же данных. Можем получить такой результат:
- Быстрая сортировка — 0,21 миллисекунда
- Сортировка выбором — 0,12 миллисекунд
Или даже такой:
- Быстрая сортировка — 0,16 миллисекунд
- Сортировка выбором — 0,17 миллисекунд
Разброс может быть достаточно большим. Дело в том, что на производительность нашей программы влияет множество случайных факторов: другие запущенные программы на компьютере, режим энергосбережения и так далее.
В работе алгоритмов много перечисленных тонкостей, поэтому сравнивать скорости довольно трудно. Чтобы справиться с этой трудностью, используем статистические методы. Будем запускать одну и ту же функцию много раз, а затем разделим общее время выполнения на количество запусков, чтобы вычислить среднее время выполнения:
Возможно вы не знакомы с конструкцией [...items], которая встречается в этом коде. Она позволяет сделать копию массива items. Без копии мы при первом же вызове функции selectionSort упорядочим массив items, и последующие вызовы будут измерять скорость сортировки уже упорядоченного массива.
У функции averagePerformance два параметра:
- Функция, чью производительность мы хотим измерить
- Количество раз, когда мы хотим ее запустить
Мы видим, что среднее время выполнения может заметно отличаться от времени, измеренного один раз — на 30% в нашем случае. Значит ли это, что теперь у нас в руках есть надежный способ сравнения алгоритмов? Кажется, что да. Но мы пока так и не выяснили, почему быстрая сортировка такая медленная по сравнению с сортировкой выбором.
Продолжим искать причину и сравним время выполнения разных сортировок на массиве из ста элементов:
На большом массиве быстрая сортировка оказывается в три раза быстрее, чем сортировка выбором! Как такое может быть? Конечно, у этой странности есть объяснение, мы обсудим его чуть позже. Сейчас обратим внимание, что измерения скорости алгоритма на одних данных ничего не говорит об его скорости на других данных.
Мы можем с большой точностью оценить время работы алгоритма на массиве из десяти элементов и при этом мы совершенно не представляем, какой окажется скорость того же алгоритма на массиве из ста тысяч элементов. Именно поэтому перед программистами встала задача — научиться оценивать скорость алгоритмов в целом.
Оценка скорости алгоритмов «в целом»
Идея оценки «в целом» пришла к нам из математики, где есть похожая задача — нужно оценивать порядок роста функций. Математики могут точно рассчитать скорость возрастания функции в любой точке, но эта информация может оказаться не очень полезной. Сравним графики двух функций:
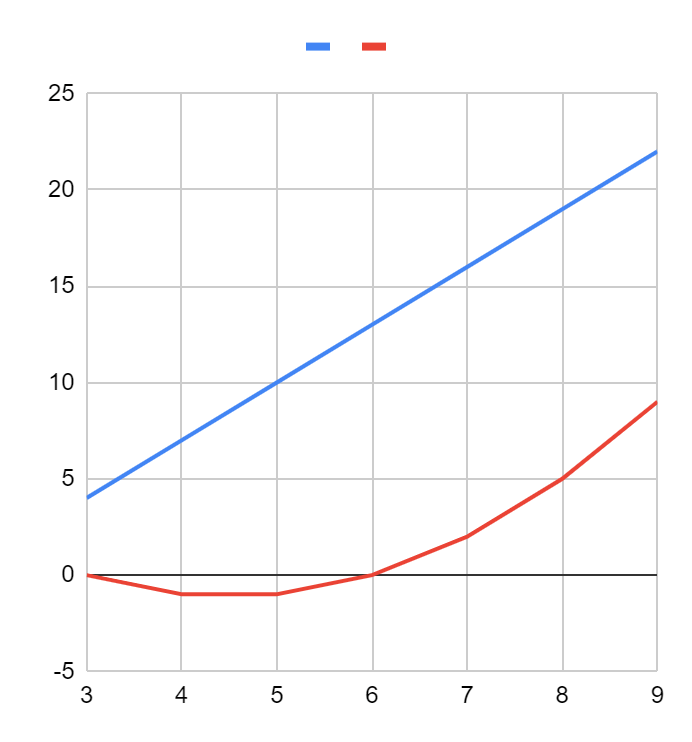
Кажется, что синяя функция больше, чем, красная. Но если посмотреть на те же графики в другом масштабе, картина изменится:
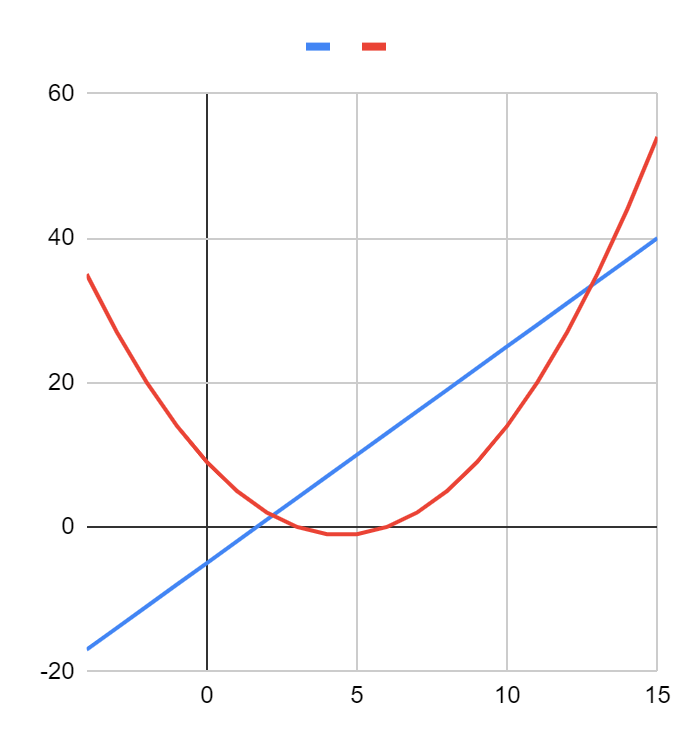
Красная функция растет гораздо быстрее и почти сразу становится больше синей. С алгоритмами возникает та же проблема: на одном наборе данных первый алгоритм физически будет быстрее второго, на многих других наборах он может оказаться гораздо медленнее. Синяя функция на графике — это прямая линия, а красная — это парабола.
Синие функции в математике принято называть линейными, а красные — квадратичными. Математики знают, что квадратичные функции растут быстрее линейных, а кубические — быстрее квадратичных.
Алгоритмическая сложность тоже бывает линейной, квадратичной и кубической. Для нее характерна та же самая зависимость: алгоритмы с квадратичной сложностью в целом работают медленнее алгоритмов с линейной сложностью. Рассмотрим несколько алгоритмов и разберемся, как определять временную сложность.
Линейная сложность
Чтобы определить временную сложность алгоритма, программисты ставят мысленный эксперимент. Предположим, что мы точно измерили время работы алгоритма на одном массиве, а потом увеличили этот массив в десять раз. Как увеличится время работы алгоритма? Если время работы алгоритма также увеличится в десять раз, то речь идет о линейной сложности — на графике она бы описывалась прямой линией.
Типичный линейный алгоритм — поиск минимального элемента в массиве:
Это простой алгоритм. Мы просматриваем элементы массива по одному и сравниваем с уже найденным. Если новый элемент оказывается меньше минимума, он становится новым минимумом. В самом начале в качестве минимума выбираем самый первый элемент массива с индексом 0. Функция состоит из двух смысловых элементов. Первый элемент — инициализация:
Второй элемент — это цикл:
Если в массиве 10 элементов, цикл выполнится 9 раз, если 100 элементов — 99 раз, если n элементов, цикл выполнится n-1 раз. В итоге, для массива из n элементов функция выполнит n операций — одну операцию инициализации и n-1 операций в цикле. Если увеличить размер массива в 10 раз, то количество элементов будет равно 10*n, и количество операций также будет равно 10*n, то есть тоже вырастет в 10 раз.
Такая линейная временная сложность обозначается O(n). Из-за того, что в записи используется большая буква O, она называется «нотация О-большое». Буква O появилась здесь не случайно. Это первая буква немецкого слова Ordnung, которое означает порядок. В математике, откуда пришло обозначение, оно относится к порядку роста функций.
Какие еще алгоритмы имеют линейную временную сложность? Например, алгоритм вычисления среднего арифметического:
Анализ алгоритма показывает, что для массива из n элементов будет n+1 операция: одна инициализация плюс n операций в цикле. Кажется, что такая временная сложность должна записываться O(n+1). Однако такие варианты, как n-2, n+5 и даже n+1000, всегда записывают как O(n). На первый взгляд это кажется странным, но далее мы разберемся, почему это так. А пока рассмотрим еще один линейный алгоритм — алгоритм определения строк-палиндромов.
Палиндромом называется строка, которая одинаково читается слева направо и справа налево. АНА и ABBA — это палиндромы, а YES и nO — нет:
В этом алгоритме цикл выполняется n/2 раз, где n — длина строки. Казалось бы, сложность работы алгоритма должна быть равна O(n/2). Но, как и в прошлый раз, это не так. Алгоритмы со временем работы 2n, 10n, n/5 и n/32 — все имеют сложность O(n), и снова это кажется странным.
Квадратичная сложность
Квадратичную сложность имеют все простые алгоритмы сортировки. Рассмотрим, например, сортировку выбором. Внутри нее есть вложенный цикл.
Чтобы избавиться от несущественных деталей, в коде выше убрана часть операций — вместо них пустые комментарии. Попробуем оценить количество выполнений цикла. На первом шаге внешнего цикла внутренний выполнится на один раз меньше, чем общее количество элементов, на втором — на два раза меньше, на третьем — на три раза меньше и так далее.
Суммарное количество выполнений цикла можно выразить как сумму чисел от 1 до n-1. Эта сумма равна половине произведения количества элементов на количество элементов минус один. Таким образом, общее количество операций пропорционально квадрату количества элементов.
Для расчетов мы использовали формулу суммы членов арифметической прогрессии. Среди слагаемых есть компонент, который растет как квадрат количества элементов, так что речь идет о квадратичной сложности, которая записывается как O(n^2). И снова встает вопрос: почему мы игнорируем деление на два и вычитаемое? Настало время разобраться.
Как мы уже говорили, алгоритмическая сложность позволяет сравнивать алгоритмы «в целом». Можно утверждать, что все линейные алгоритмы в целом быстрее всех квадратичных, хотя на конкретных данных возможны аномалии. Все квадратичные алгоритмы в целом быстрее всех кубических.
К сожалению, сравнивая два линейных алгоритма, мы не можем сказать, какой из них быстрее. Есть соблазн использовать запись вида O(4n+1) или O(2n-3), но она толкает нас на путь ложных выводов. Определяя алгоритмическую сложность, мы считаем количество операций и предполагаем, что все они выполняются за небольшое постоянное время.
Но как только речь заходит о конкретике, выясняется, что операция сложения может быть очень быстрой, а операция деления — очень медленной по сравнению со сложением. Иногда четыре сложения могут выполниться быстрее, чем два деления. Поэтому нельзя в общем случае утверждать, что O(2n - 3) быстрее, чем O(4n + 1).
Именно поэтому программисты и математики избавляются от деталей в нотации O-большое. Записи вида O(2n-3), O((n^2)/3)+5) и O(20(n^4)-1000) превращаются в O(n), O(n^2) и O(n^4) соответственно.
Какая еще бывает сложность
Теоретически мы можем придумать алгоритмы с любой экзотической сложностью, но на практике чаще встречается всего несколько вариантов.
Константная сложность
Она обозначается O(1). Алгоритмы с константной временной сложностью выполняются за одно и то же время вне зависимости от количества элементов. Например, в упорядоченном массиве минимальный элемент всегда находится в самом начале, поэтому поиск минимума становится тривиальным:
Эта функция всегда выполняется за одно и то же время, независимо от размера массива sortedItems. Формально, константные алгоритмы считаются самыми быстрыми.
Логарифмическая сложность
Обозначается O(logn). За логарифмическое время работает алгоритм бинарного поиска. Эти алгоритмы относятся к быстрым, поскольку логарифмическая функция растет достаточно медленно.
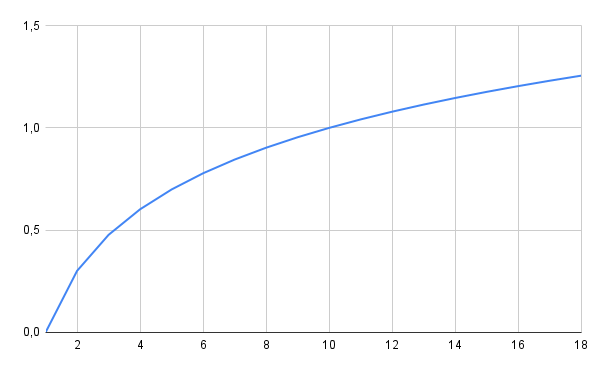
В массиве из тысячи элементов бинарный поиск работает максимум за десять сравнений, а массиве из миллиона — максимум за двадцать. Обычный метод перебора имеет линейную сложность, и поэтому будет работать за тысячу и миллион сравнений соответственно:
Логарифмические алгоритмы считаются очень быстрыми, гораздо быстрее линейных.
Линейно-логарифмическая сложность
Она обозначается как O(nlogn) и описывает сложность алгоритма быстрой сортировки. Сравним количество операций у быстрой сортировки и сортировки выбором — так мы увидим, почему быстрая сортировка так называется:
Быстрая сортировка упорядочивает массив из тысячи элементов приблизительно за десять тысяч операций, в то время как сортировка выбором — за миллион. Время выполнения различается в сто раз, и с ростом n разница только растет! Но важно не забывать, что на очень маленьких массивах (из десяти элементов) сортировка выбором может оказаться быстрее. Так происходит потому, что алгоритм сортировки выбором проще. Быстрая сортировка сложнее, и накладные расходы в реализации оказываются слишком велики для небольшого набора данных.
Линейно-логарифмическая сложность медленнее линейной, но быстрее квадратичной.
Экспоненциальная сложность
Сколько подмассивов можно получить из массива [1, 2, 3, 4]? Попробуем выяснить, но сначала определимся с условиями:
- Подмассивы могут быть любой длины, включая ноль
- Будем считать одним подмассивом все подмассивы, состоящие из одних и тех же элементов в разном порядке (например,
[1,2]и[2,1])
Выпишем все варианты и посчитаем их:
Всего 16. Существует общее правило, по которому возможное количество подмассивов у массива длины n составляет 2^n. Формулы вида 2^n, 3^n, 100^n называют экспонентами. Алгоритм, который может построить список всех подмассивов массива длины n, имеет экспоненциальную сложность O(2^n).
Алгоритмы экспоненциальной сложности считаются медленными. Количество подмассивов у массива из тридцати элементов равно 1073741824, то есть превышает миллиард!
Факториальная сложность
Обозначается O(n!). Факториалом числа n называют произведение 1 × 2 × ... × n, то есть всех чисел от 1 до n. Сложность алгоритма, который находит все перестановки массива, равна O(n!). Вот все перестановки массива [1, 2, 3, 4]:
Всего их 4!=24. Факториальная сложность самая медленная из тех, что мы рассмотрели. Если нам потребуется найти все перестановки массива из тридцати элементов, их окажется 265252859812191058636308480000000, то есть 265 миллионов миллионов миллионов миллионов миллионов. Даже на самом быстром современном компьютере поиск всех перестановок займет миллионы миллионов лет.
Сводная таблица временной сложности
Иногда в литературе можно встретить название полиномиальные алгоритмы — к ним относят алгоритмы со сложностью O(n^2), O(n^3) или O(n^100). Условная граница между медленными и быстрыми алгоритмами проходит между полиномиальными и экспоненциальными алгоритмами.
Оценка памяти
В нотации О-большое также оценивается память, которую потребляет алгоритм. На практике здесь редко встречаются большие значения.
Если алгоритму для работы нужно несколько переменных, которые не зависят от размеров данных, сложность по памяти составляет O(1). Такую сложность имеют алгоритмы поиска минимума и вычисления среднего арифметического. Логарифмическая сложность O(log n) встречается у рекурсивных алгоритмов, которые разбивают массив на два подмассива. Среди рассмотренных нами алгоритмов к этому классу относятся бинарный поиск и быстрая сортировка.
Линейная сложность O(n) означает, что алгоритм во время работы сохраняет дополнительные данные, размер которых соизмерим с входными данными. Например, если мы хотим избавиться от дубликатов в массиве, мы можем хранить просмотренные элементы в структуре множество (Set):
Этих неповторяющихся элементов будет чуть меньше, чем элементов в исходном массиве. Но при этом размер множества будет соизмерим с размером массива, поэтому речь идет о линейной сложности по памяти.
Оптимизация
Одна из задач, которую регулярно решают программисты — оптимизация программы. Пользователи хотят, чтобы программа работала быстрее или занимала меньше памяти.
Неопытные программисты часто пытаются оптимизировать отдельные конструкции в программах, не обращая внимания на производительность в целом. Опытные же программисты оценивают сложность существующего алгоритма. Задача оптимизации сводится к тому, чтобы найти или придумать новый алгоритм с меньшей сложностью.
Разберем пример с определением простоты числа. Простые числа имеют важное значение в криптографии и кодировании, так что программистам время от времени нужен список простых чисел или функция, которая определяет, является ли число простым.
Определение простых чисел и звучит очень просто — простые числа делятся на себя и на единицу. Но проверить число на простоту уже сложнее — попробуйте, например, выяснить — простое ли число 1073676287?
Для определения простоты числа можно использовать один из самых древних, известных человечеству, алгоритмов — Решето Эратосфена. Сначала мы записываем список чисел, начиная с двойки:
Берем первое число — двойку. Выделяем цветом числа, которые делятся на нее. Саму двойку не выделяем:
Следующее неотмеченное число — три. Выделяем цветом числа, которые делятся на три, но не саму тройку:
Четверка зачеркнута — она делится на два, поэтому мы ее пропускаем.
Переходим к пятерке. У нас уже отмечены числа 10, 20 (оба делятся на два) и 15 (делится на три). Единственное неотмеченное число — это 25. Это подсказка, которая помогает понять одну важную мысль — чтобы составить список простых чисел вплоть до n, достаточно повторить эту процедуру только для чисел от 2 до sqrt(n).
Сама процедура выделения чисел на каждой итерации пробегает n чисел. Итого, выходит n чисел на итерацию и sqrt(n) итераций. Сложность алгоритма по времени равна O(n * sqrt(n)) или в более математической записи — O(n^(3/2)). При этом нам приходится выделять память для всех n чисел, поэтому сложность по памяти равна O(n).
Решето Эратосфена — сложный алгоритм, как по времени, так и по памяти.
Чтобы оптимизировать решение, мы должны найти или придумать другой алгоритм. Обратим внимание, что Решето строит список простых чисел от 2 до n, но нам нужно только последнее число n. Мы можем проверить, что число не делится ни на какие целые числа от 2 до n-1:
Этот алгоритм линейный по времени, он работает за O(n). Он константный по памяти, O(1), поскольку количество потребляемой памяти не зависит от n.
Он работает гораздо быстрее Решета, но все еще не самый оптимальный. Как мы помним, для проверки нам не обязательно делить n на все числа меньше себя, достаточно проверить только числа от 2 до sqrt(n), так что алгоритм можно переписать.
Алгоритмическая сложность переписанного алгоритма равна O(sqrt(n)) или O(n^(1/2)).
Выводы
- При общих равных условиях программисты выбирают самые быстрые и самые экономичные алгоритмы
- Выбрать самый быстрый алгоритм оказывается не так просто. Измерения на конкретных данных не позволяют прогнозировать время и память алгоритмов на других данных
- Программисты используют нотацию О-большое, чтобы оценить производительность алгоритмов в целом
- Чаще всего встречаются такие сложности, как константная, логарифмическая, линейная, линейно-логарифмическая, квадратическая, экспоненциальная и факториальная. В этом списке они распределены в порядке от самой быстрой к самой медленной
- Нотация О-большое оценивает не только скорость алгоритма, но и память, которую он использует
Рекомендуемые программы

Завершено
0 / 9