Алгоритмы на деревьях
Теория: Бинарные деревья
Организация хранения данных в виде дерева позволяет обойти ограничения линейной структуры данных. Например, в последней нельзя организовать быстрыми поиск и вставку элементов одновременно. При этом в иерархической структуре данных можно эффективно выбирать и обновлять большие объемы данных.
Один из наиболее часто используемых и простых в реализации подвидов деревьев — бинарные деревья. Помимо организации поиска, бинарные деревья используют, когда разбирают математические выражения и компьютерные программы. Еще их используют, чтобы хранить данные для алгоритмов сжатия, а также они лежат в основе других структур данных, например, очереди с приоритетом, кучи и словари.
В этом уроке мы познакомимся с устройством и особенностями бинарных деревьев и разберем основные операции с его узлами.
Что такое бинарные деревья
Бинарное дерево или двоичное дерево — это дерево, в котором у каждого из его узлов не более двух дочерних узлов. При этом каждый дочерний узел тоже представляет собой бинарное дерево.
Рассмотрим примеры деревьев на следующем рисунке:
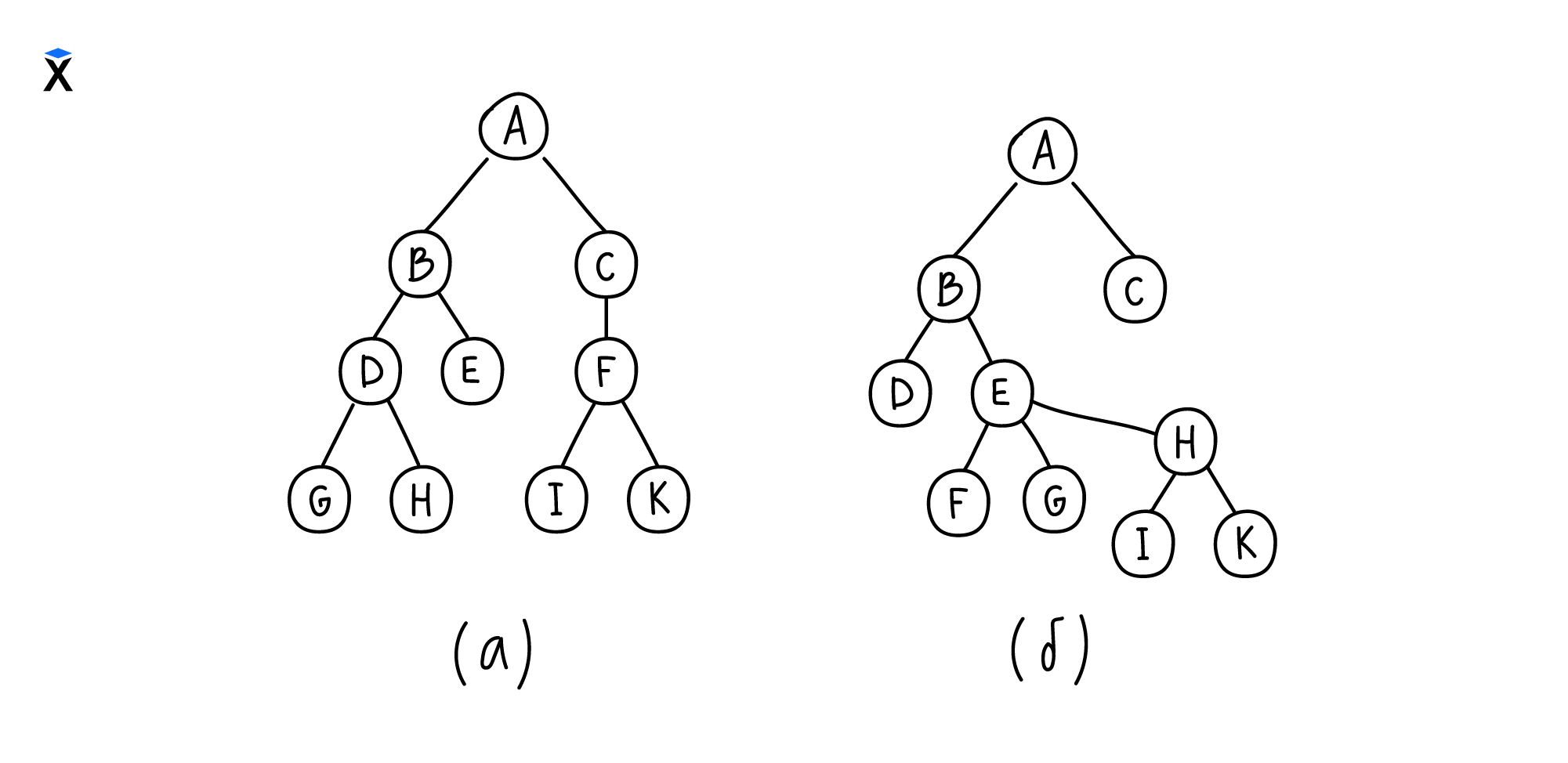
Дерево (а) — бинарное. У каждого его узла не более двух дочерних узлов, у каждого из которых тоже не более двух дочерних. Например, узлы E, G, H, I и K — листовые, значит, у них ноль дочерних узлов. У узла C только один дочерний узел, а у узлов A, B, D и F по два дочерних.
Как только правило двух дочерних нарушается, то дерево перестает относиться к классу бинарных. Так, дерево (б) не является бинарным, так как у узла E три дочерних узла.
Благодаря тому, что дочерних узлов всегда не больше двух, их называют правый и левый дочерние узлы.
Напомним, что есть завершенное и полное деревья. Для бинарных деревьев они приобретают следующий вид:
- Завершенное бинарное дерево — это бинарное дерево, в котором каждый уровень, кроме последнего, полностью заполнен, а заполнение последнего уровня производится слева направо
- Полное бинарное дерево — это бинарное дерево, в котором у каждого узла ноль или два дочерних узла
На практике чаще применяются два подвида бинарных деревьев: бинарные деревья поиска и бинарные кучи. Последние разберем в следующих уроках, а в этом сосредоточимся на первых.
Что такое бинарные деревья поиска
Бинарные деревья поиска отличаются от обычных бинарных деревьев тем, что хранят данные в отсортированном виде. Хранение значений внутри бинарного дерева поиска организовано в следующем виде:
- Все значения в узлах левого дочернего поддерева меньше значения родительского узла
- Все значения в узлах правого дочернего поддерева больше значения родительского узла
- Каждый дочерний узел тоже является бинарным деревом поиска
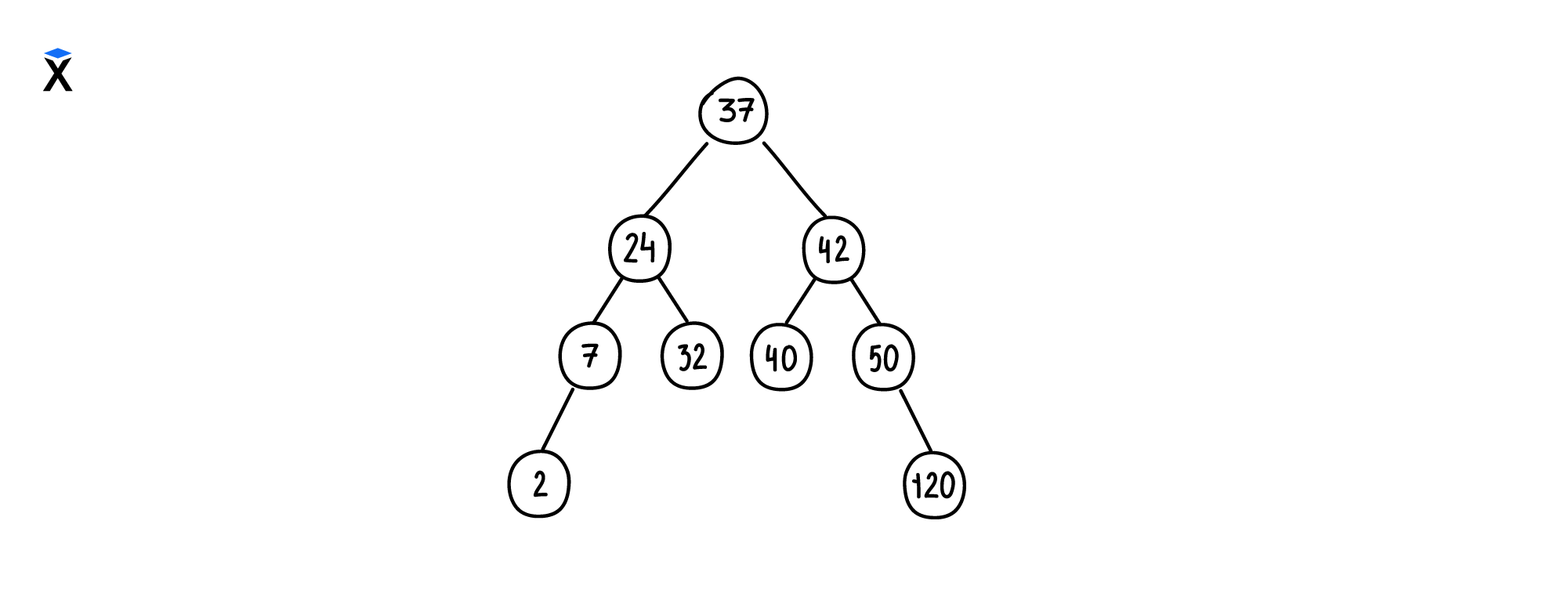
Благодаря такой структуре хранения данных поиск узла в бинарном дереве поиска занимает O(logN). Это значительно меньше, если хранить значения в списках — O(N).
Если использовать отсортированный массив для хранения данных, скорость поиска элементов сравняется. Но при оценке времени вставки хранение в массиве значительно проигрывает работе с деревьями — O(N) против O(logN) соответственно.
Такая высокая эффективность поиска в бинарном дереве поиска наблюдается только при сохранении его в сбалансированном состоянии — когда все уровни, кроме последнего полностью заполнены. Это значит, что любое добавление или удаление вершины может потребовать полное перестроение дерева. Более подробно об этой особенности мы поговорим в следующем уроке.
Рассмотрим на примере поиска элемента (10) сравнение операций поиска в отсортированном массиве, списке и бинарном дереве поиска:
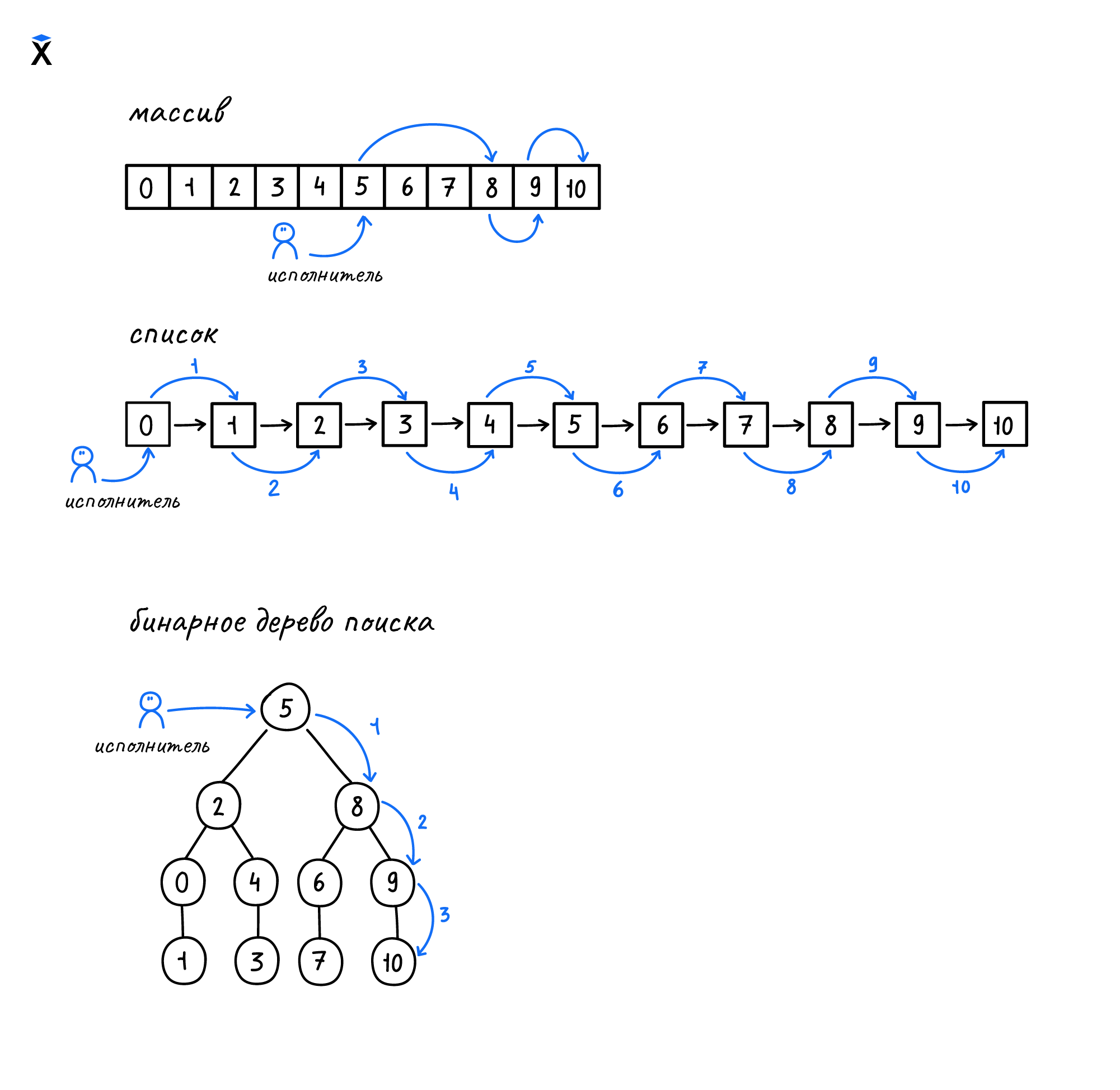
Для поиска в массиве применяется традиционный подход на основе половинного деления — метод дихотомии. На схеме можно видеть что аналогичная операция и на массиве, и на бинарном дереве поиска будет выполнена за три шага. В то же время поиск этого элемента на списке займет десять шагов.
Далее поговорим о структуре бинарных деревьев и начнем реализовывать бинарное дерево в коде.
Как бинарные деревья поиска реализуются в коде
Напомним свойства бинарных деревьев:
- Должно быть не более двух дочерних узлов
- Дочерние узлы тоже должны быть бинарными деревьями
- Дочерние узлы называют левыми и правыми
В этом случае структура узла принимает следующий вид:
Теперь нам необходимо расширить наш класс и реализовать необходимые операции, чтобы взаимодействовать с проектируемым классом. Начнем с операции поиска узла.
С бинарными деревьями поиска можно выполнять следующие операции:
- Искать узел
- Вставлять узел
- Удалять узел
- Выполнять обход дерева
Разберем каждую операцию подробнее.
Поиск узла
Если искомое значение бинарного дерева поиска меньше значения узла, то оно может находиться только в левом поддереве. Искомое значение, которое больше значения узла, может быть только в правом поддереве. В таком случае мы можем применить рекурсивный подход и операция поиска будет выглядеть так:
Вставка узла
Все значения меньше текущего значения узла надо размещать в левом поддереве, а большие — в правом. Чтобы вставить новый узел, нужно проверить, что текущий узел не пуст. Далее может быть два пути:
- Если это так, сравниваем значение со вставляемым. По результату сравнения проводим проверку для правого или левого поддеревьев
- Если узел пуст, создаем новый и заполняем ссылку на текущий узел в качестве родителя
Операция вставки использует рекурсивный подход аналогично операции поиска. Переведем данный алгоритм на язык JavaScript и получим следующий код метода вставки:
Удаление узла
Чтобы удалить элемент в связном списке, нужно найти его и ссылку на следующий элемент перенести в поле ссылки на предыдущем элементе.
Если необходимо удалить корневой узел или промежуточные вершины и сохранить структуру бинарного дерева поиска, выбирают один из следующих двух способов:
- Находим и удаляем максимальный элемент левого поддерева и используем его значение в качестве корневого или промежуточного узла
- Находим и удаляем минимальный элемент правого поддерева и используем его значение в качестве корневого или промежуточного узла
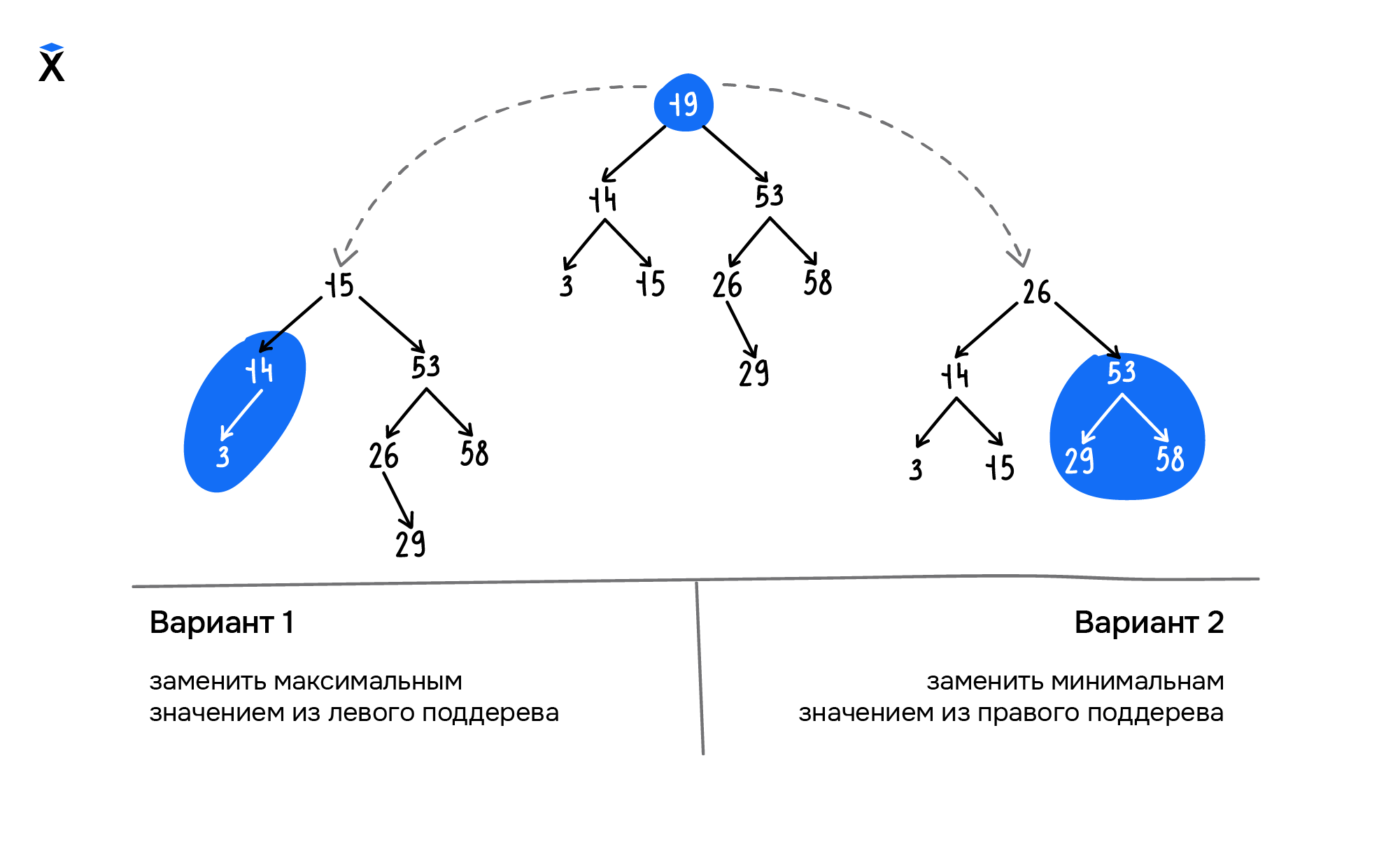
Оба варианта приемлемы для нашего дерева. Реализуем в коде второй вариант:
Реализация первого варианта будет выглядеть практически идентично. Только есть исключение: мы будем обходить правое поддерево и искать максимальное значение узла вместо минимального.
Для деревьев также существуют специфические операции, важнейшая из которых — обход дерева. Рассмотрим эту операцию подробнее.
Обход деревьев
Когда мы поработали с деревом и нам нужно его сохранить в файл или вывести в печать, нам больше не нужен древовидный формат. Здесь мы прибегаем к обходу дерева — последовательное единоразовое посещение всех вершин дерева.
Существуют такие три варианта обхода деревьев:
- Прямой обход (КЛП): корень → левое поддерево → правое поддерево
- Центрированный обход (ЛКП): левое поддерево → корень → правое поддерево
- Обратный обход (ЛПК): левое поддерево → правое поддерево → корень
Такие обходы называются поиском в глубину*. На каждом шаге итератор пытается продвинуться вертикально вниз по дереву перед тем, как перейти к родственному узлу — узлу на том же уровне. Еще есть поиск в ширину — обход узлов дерева по уровням: от корня и далее:
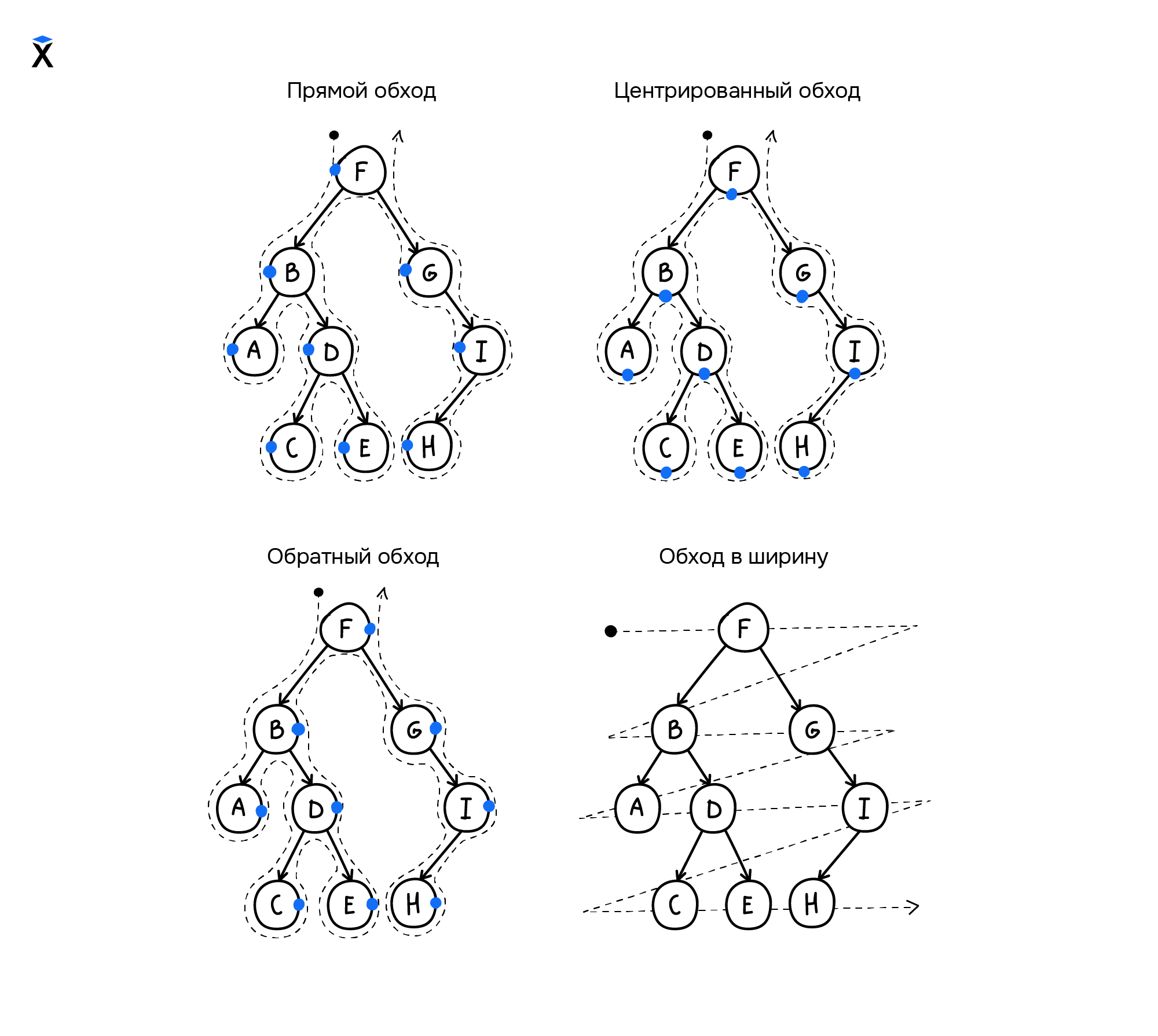
Реализация поиска в глубину может осуществляться или с использованием рекурсии, или с использованием стека. А поиск в ширину реализуется за счет использования очереди:
Выводы
В этом уроке мы познакомились с бинарными деревьями — структурой, которая лежит в основе многих других типов данных: множеств, куч, очередей с приоритетом. Еще мы подробно разобрали ключевой их подвид — бинарные деревья поиска и изучили методы работы с ними. Они позволят эффективно искать и обновлять большие объемы данных.
